I am pleased to share that my article on applying Business Machine Learning (BML) to pharmaceutical cost estimation has been published in Chemical Engineering Progress (CEP), the flagship magazine of AIChE. The article explores how BML can uncover hidden efficiencies in pharmaceutical manufacturing economics.
This case study demonstrates how machine learning can be applied to model and forecast process-level economics in semiconductor manufacturing. A simplified CMOS wafer fabrication line consisting of ten distinct steps was used to simulate time and cost parameters, forming the basis for synthetic training data. A neural network was developed to predict total wafer processing cost based on these stepwise inputs.
Using 5000 training samples and ±5% random noise, a 64-64-1 neural network architecture achieved an R² of 0.8671 and a mean absolute error (MAE) of $85.69 on unseen test data. These results are strong given that the process cost values span a range from approximately $2200 to $4200.
The model supports rapid economic inference and enables simulation of what-if scenarios across fabrication conditions. More broadly, this approach illustrates how Business ML (BML) can be applied to any structured process where time and cost parameters are distributed across sequential operations. The methodology generalizes beyond semiconductors and can be adapted to manufacturing systems, chemical processing, pharmaceutical production, and other domains where cost forecasting plays a critical decision-making role.
Introduction
Business decisions in manufacturing often depend on understanding how time, resources, and process complexity translate into economic outcomes. While many industries rely on spreadsheets or rule-of-thumb estimates to forecast costs, these methods are often slow, rigid, and poorly suited to managing complex, multistep operations. This is where Business ML (BML), the application of machine learning to economic inference, offers a compelling alternative.
This case study applies a Business ML approach to a simplified CMOS (complementary metal-oxide-semiconductor) wafer fabrication process. The semiconductor industry is well suited for cost modeling because of its highly structured process flows, detailed time and equipment usage data, and the economic sensitivity of each fabrication step. By simulating time and cost inputs across ten key process stages, a neural network model was trained to predict total wafer processing cost with strong accuracy and generalization.
Unlike traditional process optimization models that focus on physics or yield, the objective here is economic. The aim is to estimate the total cost per wafer given variations in time and cost rates across steps such as oxidation, photolithography, etching, and deposition. This reframes machine learning as a tool for business reasoning rather than scientific analysis.
The goal of this article is to demonstrate how Business ML can provide fast, scenario-ready predictions in structured process environments. It offers a way for engineers, planners, and decision-makers to simulate cost impacts without manually recalculating or maintaining large spreadsheet models. The CMOS process provides a focused example, but the methodology can be extended to any industry where costs accumulate through a sequence of measurable operations.
The CMOS Cost Modeling Problem
Wafer fabrication in CMOS semiconductor manufacturing is a highly structured, stepwise process involving repeated cycles of deposition, patterning, etching, and inspection. Each step contributes incrementally to the final product and to the total manufacturing cost. For modeling purposes, this study uses a simplified version of the CMOS flow that includes ten representative steps: Test & Inspection, Oxidation, Photolithography, Etching, Ion Implantation, Deposition, Chemical Mechanical Planarization (CMP), Annealing, Metallization, and Final Test.
Each step is modeled using two parameters:
ti, the time required to perform the step, in minutes
ci, the effective cost per minute associated with the step, which may include equipment usage, labor, power, and materials
The total wafer processing cost is modeled using the following structure:
Process Cost= c_rm + Σ(ki × ti × ci) for i = 0 to 9
where:
c_rm is the raw material cost, representing the wafer or substrate being processed
ti and ci are the time and cost for each of the ten fabrication steps
ki is an optional step weight or scaling factor, set to 1.0 in this study
This formulation mirrors the approach used in other Business ML applications, such as pharmaceutical cost modeling, where c_rm represents the cost of purchased raw materials and the summation captures stepwise transformation and processing costs.
Because detailed cost data for semiconductor process steps is often proprietary, this study relies on synthetic data generation. Reasonable upper and lower bounds for time and cost were defined for each step based on open-source literature, technical papers, and process engineering judgment. Random values were sampled within these bounds to reflect natural process variation. An additional ±5% random noise term was applied to simulate real-world uncertainty.
This modeling framework is well suited for Business ML. The process is modular, the economic output is driven by well-understood operations, and the structure aligns with common business scenarios where costs are accumulated through a sequence of steps. This enables the trained model to act as a surrogate for estimating cost outcomes without requiring manual spreadsheet calculations or custom economic models.
Model Design and Training
The goal of this model is to predict the total processing cost of a CMOS wafer based on time and cost inputs from each fabrication step. To focus specifically on operational drivers, the model is trained only on the variable portion of the cost:
Process Cost = Σ(ki × ti × ci) for i = 0 to 9
The fixed raw material cost, denoted as c_rm, is deliberately excluded from the machine learning target. While c_rm contributes to the full wafer cost, it does not depend on process dynamics, and its exclusion allows the model to learn the economic impact of process-specific variation alone.
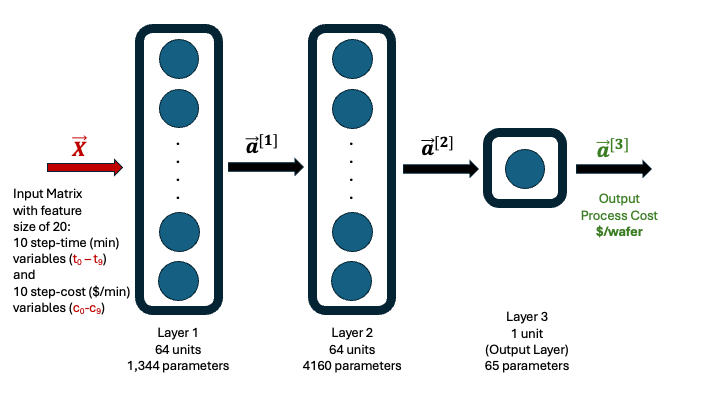
A feedforward neural network was selected for this task, using 20 input features (Table 1):
Ten step durations (ti) and ten corresponding step costs (ci)
Each input was standardized using scikit-learn’s StandardScaler
The output (process cost) was also standardized before training and later inverse-transformed for evaluation
Table 1. Summary of CMOS process step descriptions, time (ti) ranges, and cost rate (ci) ranges used for synthetic data generation
Step
Description
Time – ti (min)
Cost Rate – ci ($/min)
S0
Test & Inspection – Initial
10 – 15
3.0 – 6.0
S1
Oxidation
90 – 150
4.0 – 7.0
S2
Photolithography
25 – 45
12.0 – 20.0
S3
Etching
15 – 30
8.0 – 14.0
SS4
Ion Implantation
10 – 20
10.0 – 16.0
S5
Deposition
30 – 60
6.0 – 10.0
S6
CMP
20 – 40
5.0 – 9.0
S7
Annealing
45 – 90
5.0 – 8.0
S8
Metallization
30 – 60
7.0 – 12.0
S9
Test & Inspection – Final
10 – 25
3.0 – 6.0
The final model architecture consists of:
Two hidden layers, each with 64 neurons and ReLU activation
One output layer with a single linear neuron
Mean squared error (MSE) as the loss function
Adam optimizer with a learning rate of 0.001
Early stopping based on validation loss with a patience of 10 epochs
A visual representation of this architecture is shown below (Figure 1).
Figure 1.Architecture of the 64-64-1 neural network used to predict CMOS process cost from 20 input features. The model consists of two hidden layers with ReLU activation and a single linear output node. Standardization was applied to all features and the output using scikit-learn.
The model was trained on 5000 synthetic samples generated using uniform random sampling across step-level time and cost ranges. A ±5% random noise term was added to each sample to simulate real-world uncertainty. The dataset was split into 80% training and 20% testing, and the model achieved strong predictive performance on the test set.
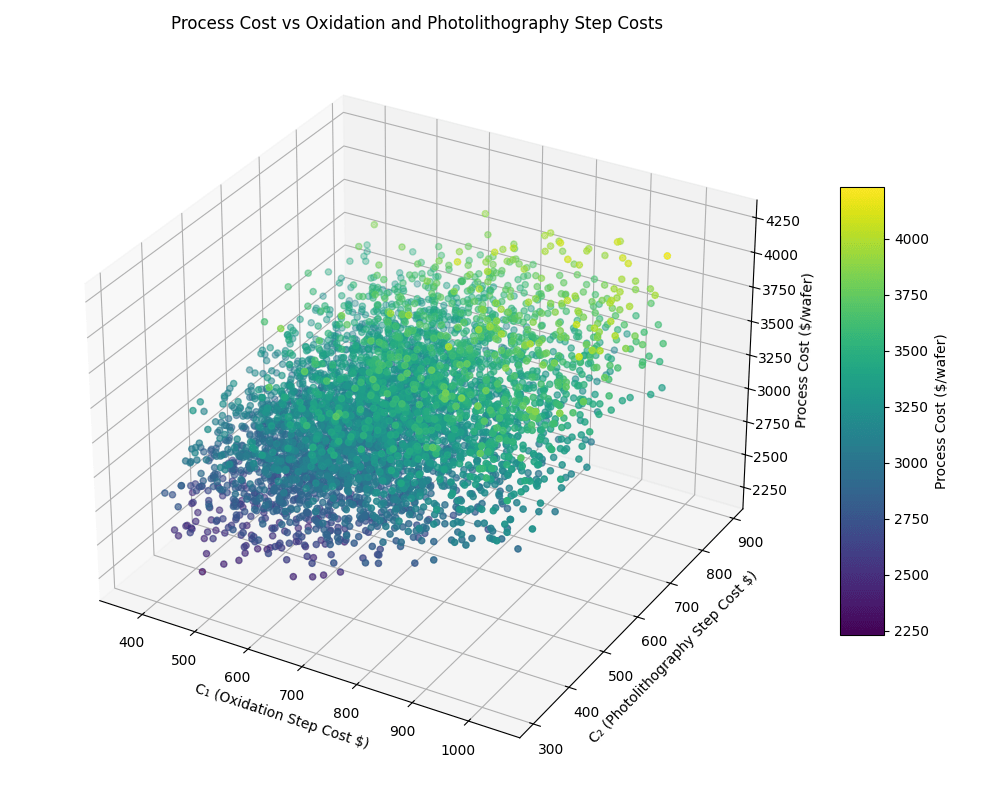
A 3D scatter plot of predicted process cost versus two representative step costs (Oxidation and Photolithography) is shown in Figure 3.
Figure 2. Process cost distribution as a function of oxidation (C₁) and photolithography (C₂) step costs. Each point corresponds to a single synthetic data sample.
This design represents a simple, generalizable Business ML framework that can be extended across other process-oriented domains. The neural network acts as a surrogate function that captures cost behavior across a space of operational inputs, without requiring manual calculations, spreadsheets, or symbolic optimization. The model was implemented using TensorFlow with the Keras API and trained on a MacBook M4 CPU without GPU acceleration. All experiments were performed in a lightweight, reproducible environment, using standard Python tools such as scikit-learn for scaling and evaluation.
Results and Evaluation
The trained model was evaluated on a holdout test set comprising 1000 samples (20% of the 5000 total synthetic records). These test samples were not seen during training and serve as an unbiased estimate of model performance.
The final model architecture, a 64-64-1 feedforward neural network trained with a batch size of 32, achieved the following results:
Test Set Performance
R² (coefficient of determination): 0.8671
Mean Absolute Error (MAE): $85.69
Mean Squared Error (MSE): 10,371.34
These results indicate that the model explains approximately 87% of the variability in process cost and predicts values with an average absolute deviation of less than $86. Considering the total process cost ranged from approximately $2230 to $4230, this represents an error of roughly 2.7% — well within a range that is useful for decision support in production planning or cost forecasting.
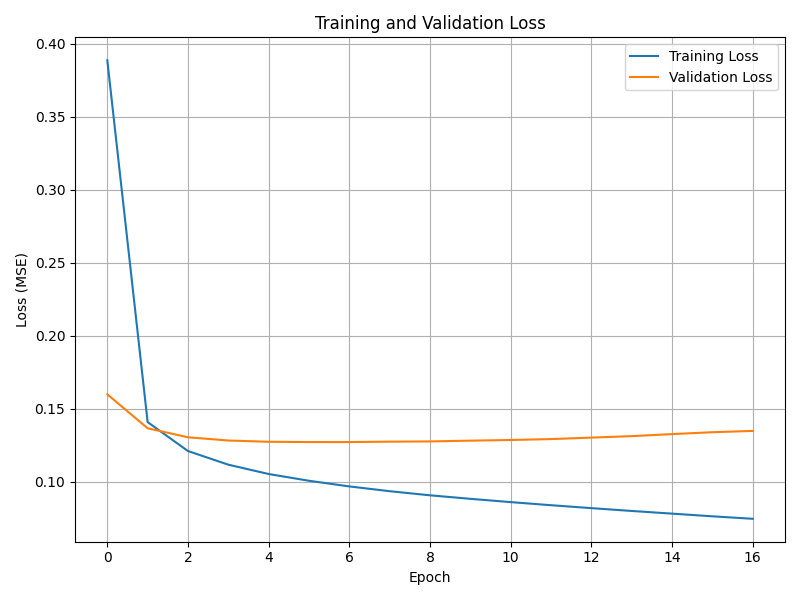
Loss Curve Analysis
Training dynamics were monitored using validation loss, with early stopping applied to prevent overfitting. The model converged after 17 epochs, with validation loss reaching its minimum at epoch 7 and no further improvement thereafter. Early stopping restored the weights from this optimal point.
Figure 3.Training and validation loss curve during model training. Early stopping restored the best weights based on the lowest validation loss.
This convergence behavior confirms that the model was not overtrained and generalizes well to unseen data.
Scenario Testing
To test the model’s flexibility and real-world applicability, seven what-if scenarios were created by adjusting process step durations and cost rates. These included edge cases such as photolithography overload, implant bottlenecks, and optimized CMP/anneal conditions. The model returned consistent, interpretable cost predictions across all cases, demonstrating its ability to simulate the financial impact of changes in operational inputs.
The model outputs wafer-level process cost values that span a realistic operating range. Across 5000 synthetic samples with 5% noise, the predicted costs ranged from $2,229.98 to $4,230.61, with a mean of $3,181.06 and standard deviation of $285.75. This range serves as the reference context for interpreting the impact of scenario changes.
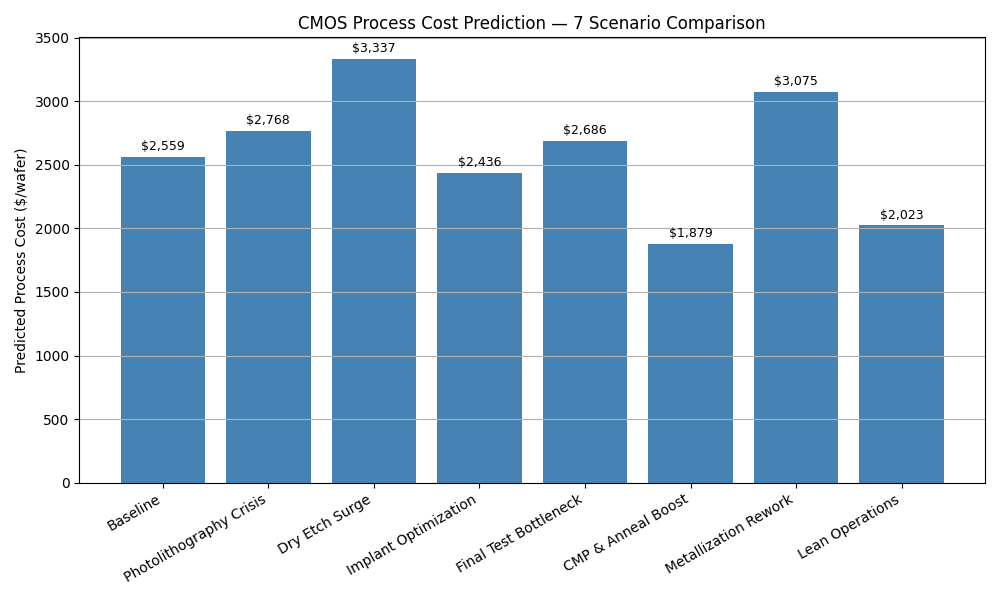
Figure 4 presents a comparison of seven scenarios designed to stress or improve different steps in the CMOS process. Each bar reflects the predicted process cost when modifying specific combinations of time and cost factors for one or more steps. These scenarios were evaluated using the trained neural network model.
Figure 4.Predicted process costs for seven scenario cases based on step-level time and cost modifications. The baseline reflects nominal midpoint values. Other scenarios simulate manufacturing disruptions (e.g., “Photolithography Crisis”) or optimizations (e.g., “Implant Optimization,” “Lean Operations”). Predictions were generated using the trained neural network model.
The baseline scenario uses the midpoint of each feature’s training range, scaled down to simulate a typical factory setting operating at 75% of nominal time and 85% of nominal cost. The baseline feature set is as follows:
All seven scenarios are derived by selectively modifying one or more of these values:
Photolithography Crisis doubles both t2 and c2 (photolithography duration and cost).
Dry Etch Surge increases t3 by 50% and c3 by 150%.
Implant Optimization reduces both t4 and c4 by 50%.
Final Test Bottleneck triples t9 and increases c9 by 50%.
CMP & Anneal Boost reduces t6, c6, t7, and c7 by 40%.
Metallization Rework doubles t8 and increases c8 by 20%.
Lean Operations reduces allti values by 15% and allci values by 10%.
These cases were designed to test the model’s responsiveness to both localized disturbances and broad efficiency improvements. The predicted costs reflect the non-linear effects of compounding time and cost variations across multiple steps.
Conclusion
This study demonstrated how a simple feedforward neural network can be used to model the economics of CMOS wafer processing using structured time and cost inputs. By simulating realistic ranges for ten key fabrication steps and adding controlled noise to mimic real-world variability, the model was able to predict wafer processing cost with strong accuracy.
The final model, trained on just 5000 synthetic records with ±5% noise, achieved an R² of 0.8671 and an MAE of $85.69. These results reflect a high level of fidelity for a process whose total cost spans approximately $2000. The model also performed well across a range of simulated what-if scenarios, enabling economic forecasts for process changes without requiring manual recalculation or spreadsheet modeling.
More importantly, the CMOS case illustrates the broader value of Business ML. This approach generalizes to any structured process where cost accumulates over a series of steps, and where time and resource variability drive economic outcomes. Unlike static cost models, Business ML can learn from historical data and capture hidden variations in timing and resource usage that influence cost outcomes in subtle ways. These patterns, often invisible in spreadsheets, are preserved in operational data and can be exploited by ML models to deliver faster, more adaptive, and more insightful cost predictions. Business ML delivers both speed and precision, helping teams move from cost estimation to real-time cost intelligence.
Call to Action
Explore the Business ML demo and see cost prediction in action
The CMOS process cost prediction model featured in this article is now available as a live demonstration.
MLPowersAI develops custom machine learning models and deployment-ready solutions for structured, multistep manufacturing environments. This includes use cases in semiconductors, chemical production, and other industries where time, cost, and complexity converge. Our goal is to help teams harness their historical process data to forecast outcomes, optimize planning, and simulate business scenarios in real time.
In addition to semiconductor cost modeling, we apply similar Business ML frameworks across a wide range of process industries, including chemicals, pharmaceuticals, energy systems, food and beverage, and advanced materials — wherever domain data can be turned into faster, smarter economic decisions.
🔗 Visit us at MLPowersAI.com 🔗 Connect via LinkedIn for discussions or collaboration inquiries.
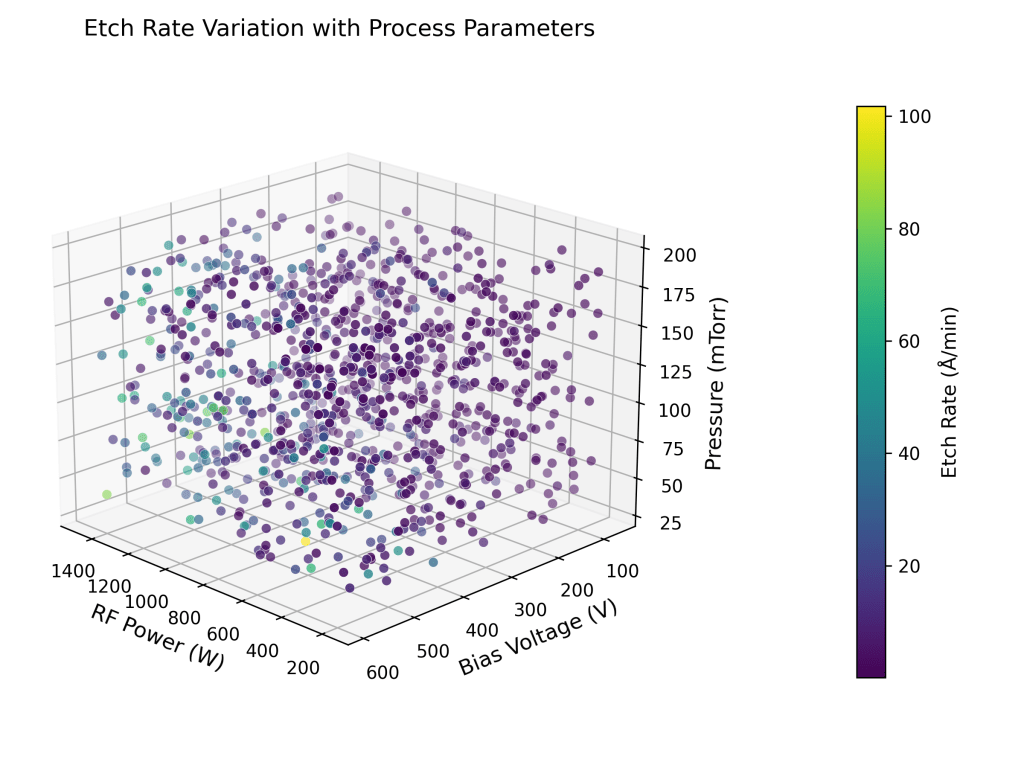
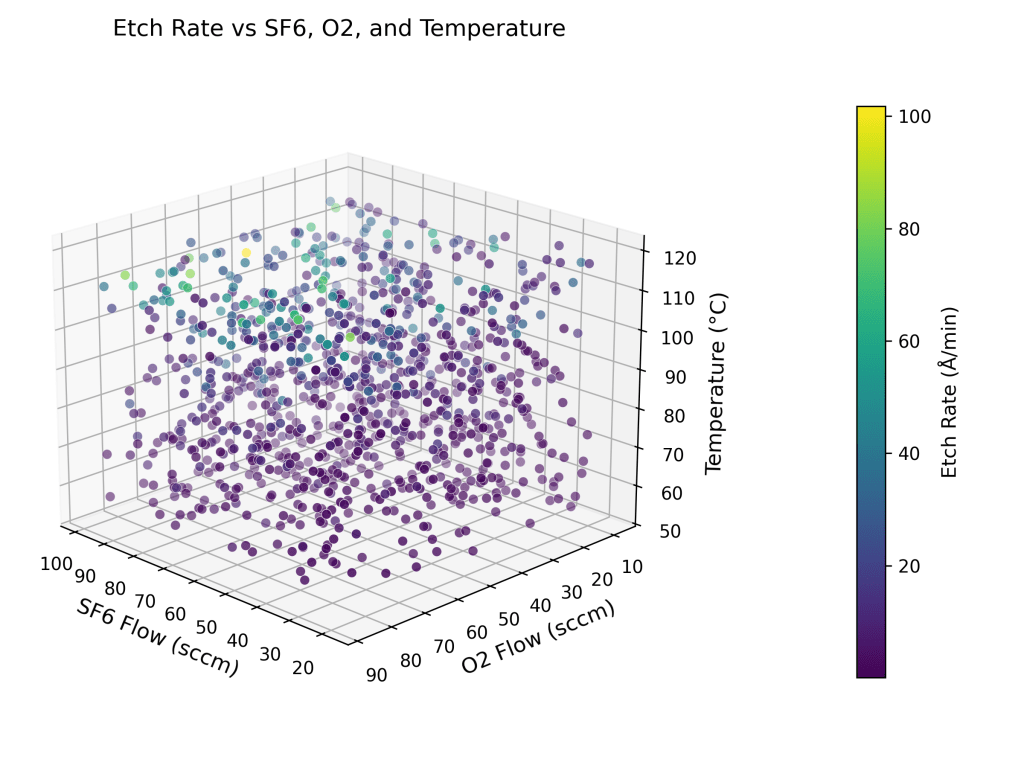
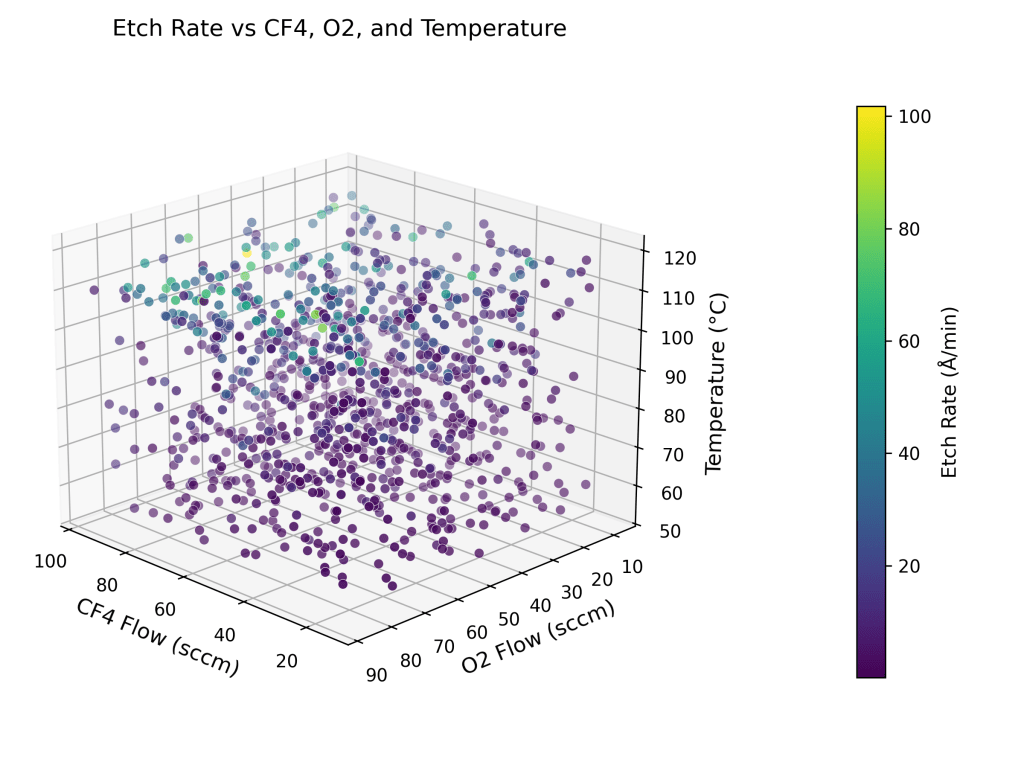
Semiconductor fabrication demands precision, consistency, and speed. In plasma etching and thin film processes, nanometer-level control directly impacts yield and device performance. Yet many fabs still rely on manual tuning and trial-based experimentation to reach optimal results. Each wafer run generates valuable process data such as chamber pressure, RF power, gas flows, temperature, and time, but much of this data remains underutilized. This article presents a machine learning (ML) solution that transforms historical process data into accurate, real-time predictions of plasma etch rates. Using a neural network trained on key operating conditions, we developed a surrogate model that consistently achieves sub-angstrom error and predicts etch outcomes with over 97% of results falling within ±5 Å/min of actual values. The model enables predictive tuning without interrupting production, replacing costly experimentation with fast, data-driven insights. This approach offers fabs a smarter, faster, and more agile method for process control. Semiconductor leaders can now convert legacy process data into strategic insights, accelerate development cycles, and unlock new efficiencies in plasma-based manufacturing.
Industry Context
Challenges in Plasma Etching and Thin Film Processing
Plasma etching is a cornerstone of semiconductor manufacturing. It enables the creation of complex nanoscale patterns on silicon wafers by precisely removing layers of material (Lam Research, n.d.). However, the process is highly sensitive to chamber conditions, recipe parameters, and tool aging effects. Minor fluctuations in RF power, gas flow rates, pressure, or temperature can significantly impact critical metrics such as etch rate, anisotropy, and uniformity (Wikipedia, 2025).
Traditionally, achieving optimal results requires extensive experimentation, often guided by a design-of-experiments (DOE) matrix. Process engineers iterate across multiple wafer runs, manually tuning parameters and analyzing results post-run. This time-intensive loop delays yield ramp-up and increases development costs. Despite advances in sensor instrumentation and data logging, much of the collected process data is used reactively rather than proactively.
With ongoing device scaling and tighter design rules, the margin for error continues to shrink. Engineers must contend with increasing complexity in high-aspect-ratio etching, evolving material stacks, and stringent critical dimension (CD) control—all while maintaining competitive cost structures. The situation is further complicated by global supply pressures and demand for faster development cycles (Lam Research, 2024). Leading equipment manufacturers, such as Applied Materials, have developed advanced etch systems like the Centris® Sym3® Etch platform to address these challenges, offering improved process control and uniformity for high-volume manufacturing (Applied Materials, n.d.).
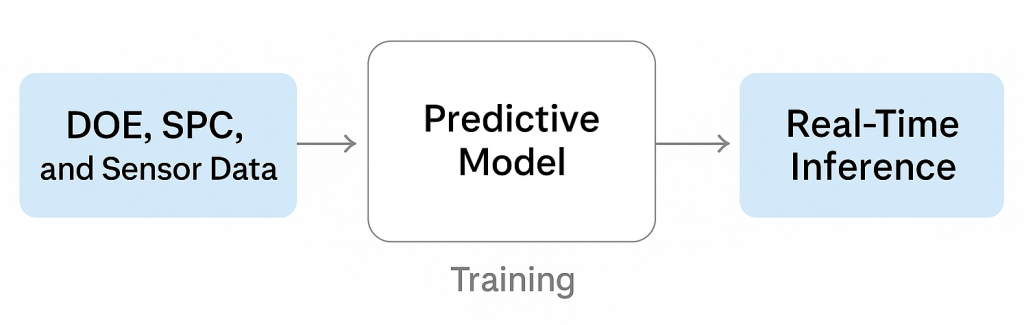
Fabs today collect terabytes of process data each month. However, this data is rarely used for predictive control. Existing models, often empirical or physics-based, can take weeks or months to calibrate—even when aided by statistical process control (SPC) techniques. Machine learning offers a new opportunity: by training models on historical DOE results, SPC trends, and sensor logs, ML-based surrogate models can deliver fast, accurate predictions that adapt to real-time input conditions. These data-driven models reduce the need for physical experiments and unlock deeper insights into process behavior and optimization potential.
The Opportunity
Turning DOE, SPC, and sensor data into predictive ML models
Machine learning presents a practical and scalable path to unlock deeper insight from the process data fabs already collect—without overhauling existing systems. Structured results from DOE matrices, parameter trends from SPC charts, and live sensor outputs from etch chambers can all serve as high-value training data for predictive models.
Rather than relying solely on static, physics-based models, an ML-driven surrogate model can learn directly from historical patterns and complex variable interactions. For example, a neural network trained on past DOE outcomes can rapidly infer etch rates for new parameter combinations—bypassing the need for repeated wafer runs. Similarly, integrating SPC trends allows the model to adjust to tool drift or seasonal shifts in performance.
Once trained, the model can be deployed for real-time inference. Engineers can use it to simulate recipe changes, optimize parameter windows, or monitor process health with predictive accuracy. This enables virtual experimentation and just-in-time tuning, dramatically reducing development cycles and wafer scrap.
More importantly, these models can evolve continuously. As new runs generate fresh data, the model can be retrained or fine-tuned—improving its accuracy and robustness over time. For fabs seeking higher throughput, tighter control, and reduced variability, machine learning transforms passive data archives into active process intelligence.
Model Development
Building a Surrogate ML Model
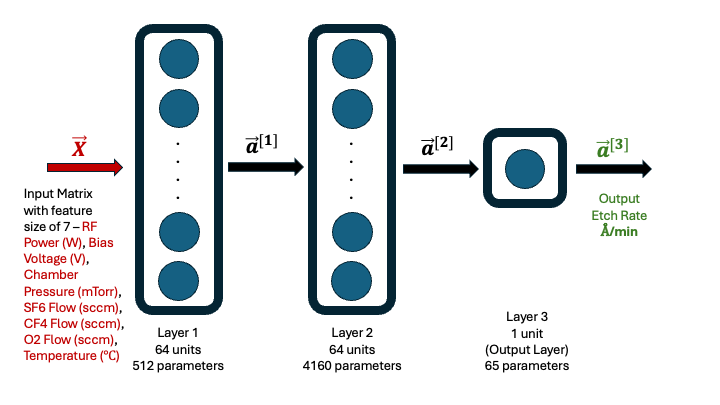
The neural network architecture used for this study is illustrated below. It consists of three fully connected layers with a total of 4,737 trainable parameters. The input layer takes in a feature vector of size 7, derived from key controllable parameters in plasma etching. The output is a single value representing the predicted etch rate (ER) in units of Ångström per minute.
In the absence of real fab data from DOE, SPC, or sensor logs, a synthetic dataset was generated using a well-structured equation inspired by formulations published in semiconductor process literature. The equation captures how etch rate (ER) depends on plasma process conditions through a combination of power-law and Arrhenius-like relationships:
The empirical constants were set at 0.8, 1.0, 0.5, 0.6, 0.4, and 0.3 respectively. are the activation energy (0.5 eV) and universal gas constant (8.617×10-5 eV/K) respectively. are the controllable process variables – plasma power (W), bias voltage (V), pressure (mTorr), flow rates of gases (sccm) and temperature (C, converted to K) respectively.
These input features were randomly varied within physically realistic bounds to generate the synthetic dataset, with corresponding etch rates computed from the above expression. This approach provided a self-consistent dataset suitable for training and evaluating the ML model in a surrogate learning context.
The synthetic dataset comprised 1,000 feature sets, each representing a unique combination of plasma etching process parameters. The corresponding etch rates were computed using the surrogate equation described earlier.
The histogram below illustrates the distribution of the computed etch rates across the full range of feature sets. As expected, the distribution reflects the non-linear dependence of etch rate on process parameters, resulting in a skewed pattern typical of many plasma process outcomes. This variability makes the dataset well-suited for training and testing the neural network model, providing a robust challenge that mirrors real-world process complexity.
To further visualize the relationship between etch rate and input parameters, three 3D scatter plots are presented below. Each plot highlights how the etch rate varies as a function of key process variables across different parameter combinations. These visualizations offer intuitive insights into the multivariate dependencies that the neural network model is designed to learn and predict.
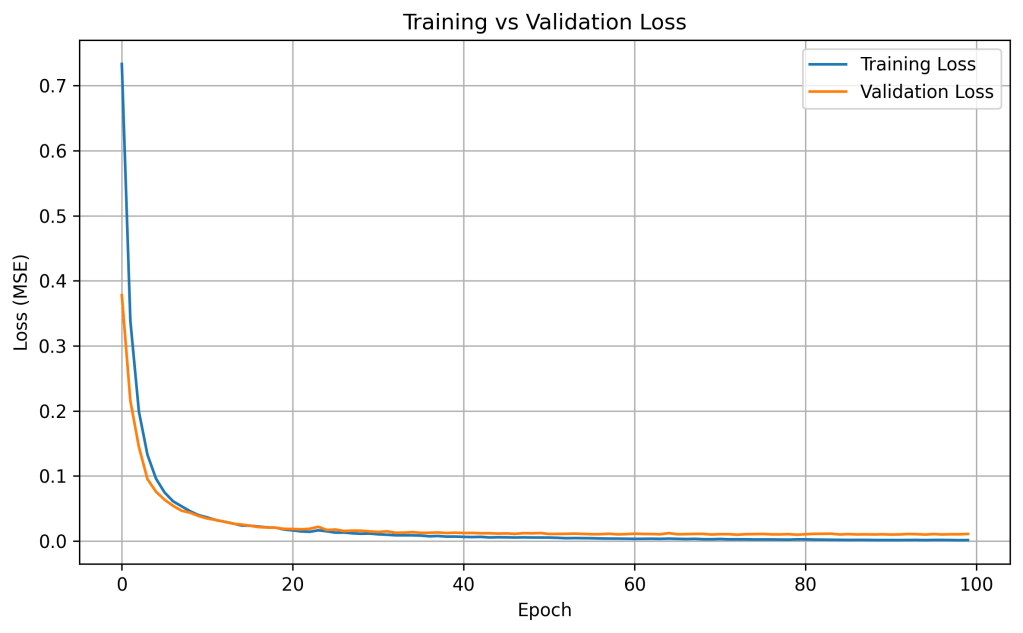
The neural network model was developed in Python using the TensorFlow library. All dense layers employed the ReLU activation function and the Adam optimizer, with mean squared error (MSE) as the loss function. The synthetic dataset was split 80:20 into training and testing subsets. During training, the model exhibited stable convergence, as shown in the loss curve below.
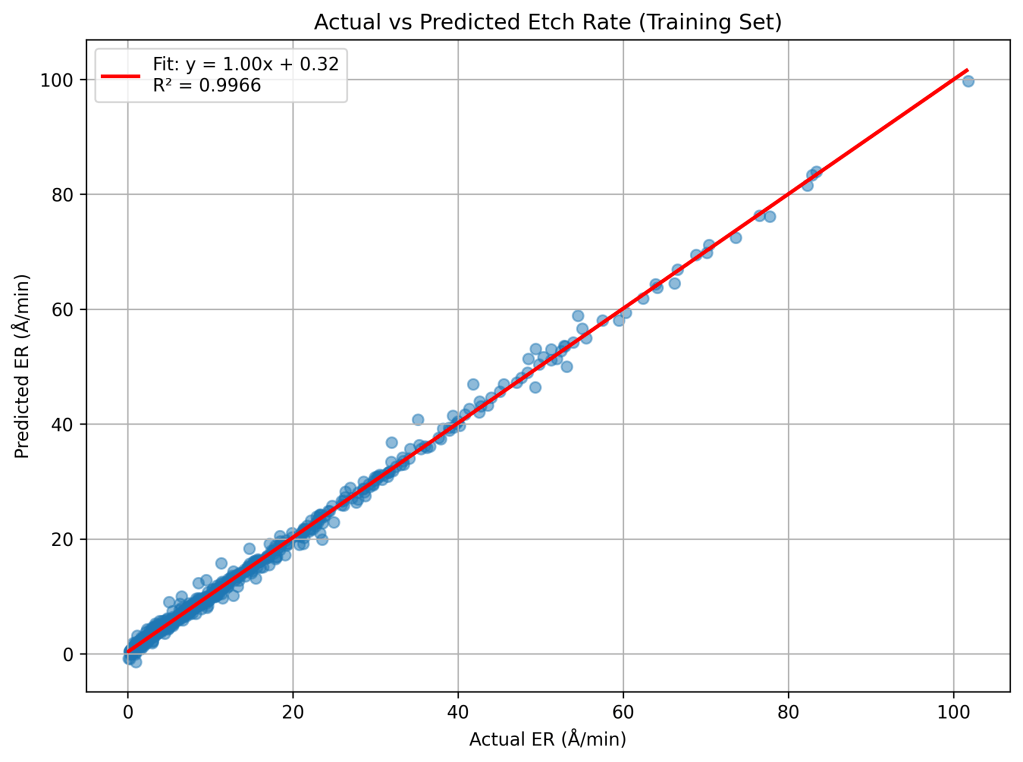
The final training performance achieved an R2 of 0.9966, MSE of 0.7459, and root mean square error (RMSE) of 0.8636 Å/min. This is an excellent fit with near unity slope.
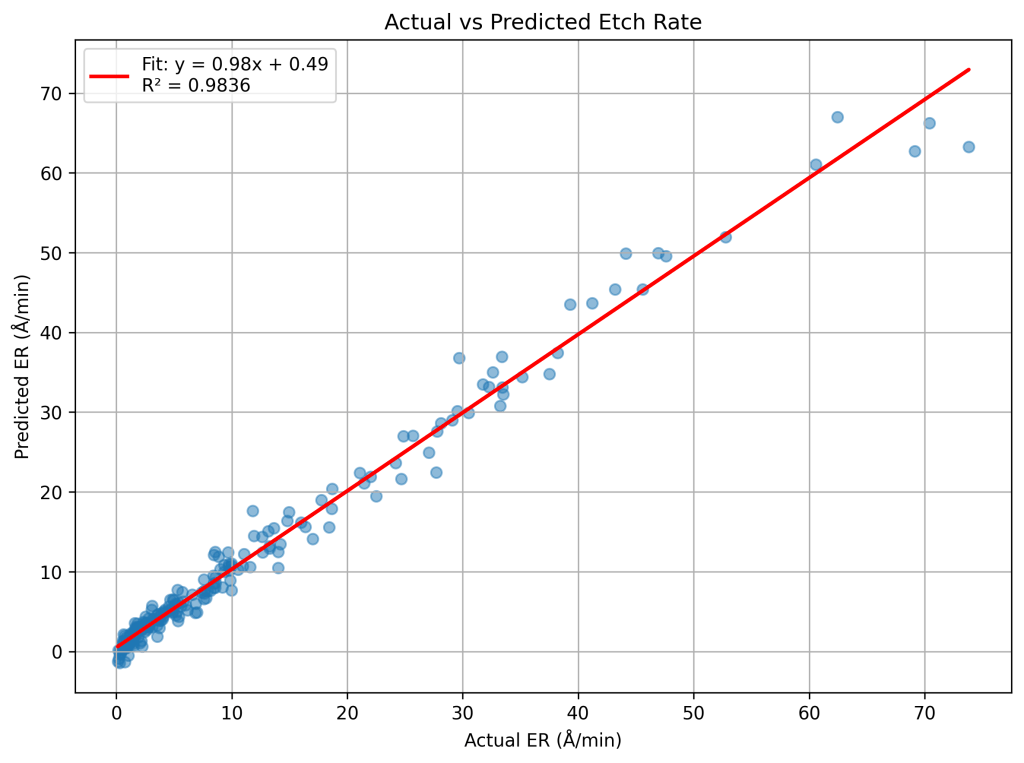
The model also demonstrated strong generalization to unseen data. On the test set, the neural network achieved an R2 of 0.9836, MSE of 3.4895, and RMSE of 1.8680 Å/min, with the regression fit again closely matching a unity slope.
Overall, the model achieved sub-angstrom accuracy across the full etch rate range during training and maintained RMSE under 2 Å/min on test data. This level of precision aligns with the resolution limits of physical metrology tools used in semiconductor fabrication, underscoring the model’s practical value as a predictive tool for low-rate plasma etching applications.
Results: Accuracy and Optimization Potential
Validating predictive performance and enabling virtual process optimization
The neural network model demonstrated high predictive accuracy across both the original training/testing dataset and a newly generated set of unseen test data.
Performance on new test data
To evaluate the model’s generalization ability, a fresh set of 300 synthetic feature sets was created, covering the same process parameter ranges used during training. The model’s predictions on this new data yielded the following results:
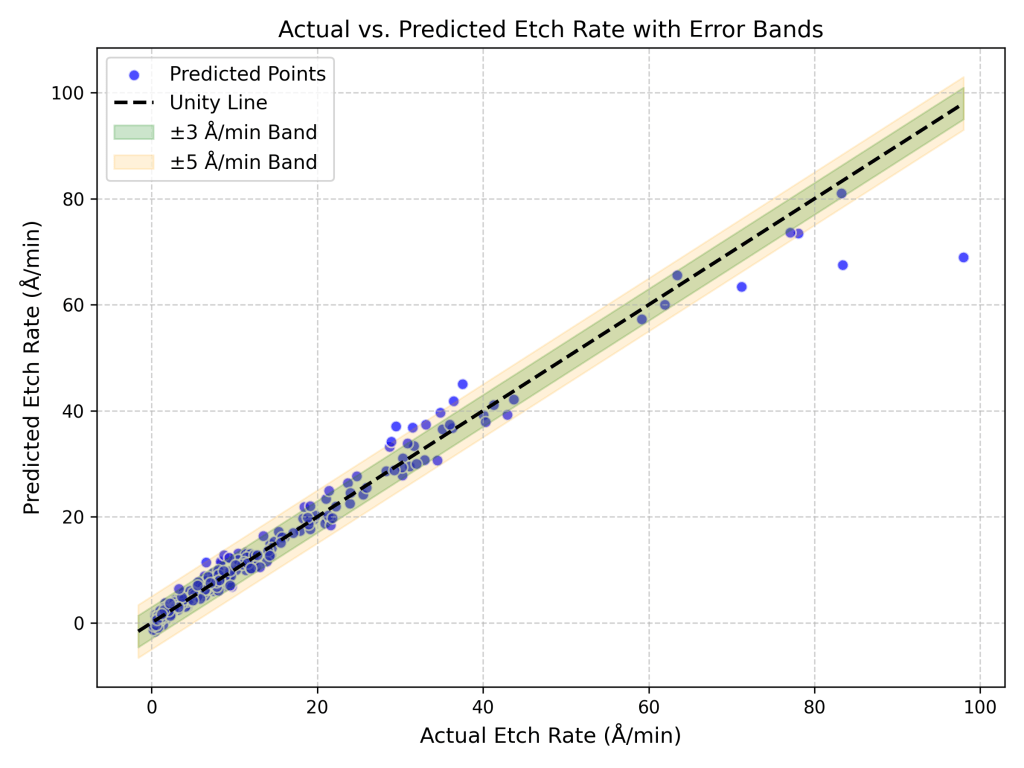
Mean Absolute Error (MAE): 1.29 Å/min
Maximum Absolute Error: 29.06 Å/min
92.67% of predictions within ±3 Å/min
97.33% of predictions within ±5 Å/min
The scatter plot below compares the actual and predicted etch rates, with shaded error bands at ±3 Å/min and ±5 Å/min. The majority of predictions fall within these bands, especially for etch rates below 80 Å/min, which represents the primary process window of interest for many plasma etching applications.
Optimization potential
This level of accuracy makes the neural network model a viable surrogate model for process optimization tasks:
Virtual recipe tuning: Engineers can predict outcomes for new parameter combinations without running physical experiments.
Parameter screening: Potentially viable process windows can be identified quickly, reducing experimental overhead.
Real-time recommendations: Once deployed, the model can suggest operating points likely to meet target etch rates, improving process agility.
Real-time recommendations: Once deployed, the model can suggest operating points likely to meet target etch rates, improving process agility.
Accelerate development cycles
Reduce wafer losses due to suboptimal tuning
Lower process development costs
The surrogate model’s strong performance in both interpolation and slight extrapolation scenarios indicates its robustness and practical utility in semiconductor process engineering environments.
Implications for Semiconductor Manufacturing
Leveraging ML models for real-time control, virtual experiments, and digital twins
The demonstrated surrogate model, with its validated accuracy and robustness, has clear implications for advancing semiconductor process development and control.
Real-Time Feedback Control
By integrating the trained neural network into process control systems, fabs can:
Predict etch rate outcomes in real time as process parameters vary.
Detect drift or tool variability before it impacts yield.
Recommend parameter adjustments to maintain target etch rates without interrupting production.
Virtual Experiments and Parameter Tuning
The model enables virtual design of experiments (vDOE), allowing engineers to:
Explore process windows computationally, reducing the need for costly wafer runs.
Evaluate “what-if” scenarios quickly when adjusting RF power, bias voltage, gas flows, or other parameters.
Optimize recipes while minimizing development time and experimental expense.
Digital Twins of Plasma Systems
This surrogate model can serve as a foundational element in building digital twins for plasma etch chambers:
Pairing real-time process data with predictive models allows continuous monitoring and optimization.
Virtual twins can simulate outcomes for new device architectures or material stacks without hardware modifications.
Facilitates predictive maintenance by forecasting when processes may move out of tolerance.
Operational Benefits
Adopting this ML-based approach can deliver:
Reduced process development cycles.
Lower wafer scrap rates.
Improved process agility when adapting to new designs or materials.
Deployment Flexibility
The trained model’s modest computational requirements allow flexible deployment:
Edge deployment: Integration with tool controllers for real-time predictions at the equipment level.
Cloud deployment: Use in broader fab-wide analytics and optimization platforms.
Conclusion: From Proof-of-Concept to Real-World Adoption
Demonstrating accuracy, speed, and scalability for next-generation plasma etch control
This study has demonstrated how a machine learning surrogate model can accurately predict plasma etch rates using key process parameters. Trained on a synthetically generated dataset modeled after realistic DOE, SPC, and sensor data, the neural network achieved sub-angstrom prediction errors across both training and new, unseen test data. The model generalized well, with over 92% of predictions falling within ±3 Å/min and 97% within ±5 Å/min, aligning with the precision levels required in modern semiconductor fabrication.
Beyond statistical performance, the model’s real-world value lies in its ability to:
Reduce reliance on costly and time-consuming physical experiments.
Enable virtual recipe tuning and rapid parameter screening.
Support the development of digital twins and real-time process control systems.
The modest computational demands of the model make it suitable for both edge deployment on individual tools and cloud-based integration into fab-wide optimization platforms.
Looking ahead
As semiconductor manufacturing continues to confront the challenges of tighter design rules, new materials, and accelerated production timelines, machine learning offers a path to smarter, faster, and more adaptive process control.
Fabs that embrace AI-driven modeling will gain a competitive edge in efficiency, yield, and innovation.
The proof-of-concept presented here demonstrates that accurate, scalable, and practical ML solutions are not just theoretical — they are ready for real-world adoption.
Call to Action
Explore the live demo and discover custom ML solutions for your fab
The plasma etch rate prediction model featured in this article is now available as a live demonstration.
MLPowersAI develops custom machine learning models and deployment-ready solutions tailored to the unique challenges of semiconductor manufacturing and thin film processes. Our goal is to help fabs leverage their existing process data to unlock new efficiencies, improve yield, and accelerate development cycles.
In addition to semiconductor applications, we apply similar approaches to deliver custom ML models across a range of process industries, including chemical manufacturing, pharmaceuticals, food and beverage, energy systems, materials processing, and other sectors where complex process data can be transformed into actionable insights and predictive solutions.
🔗 Visit us at MLPowersAI.com 🔗 Connect via LinkedIn for discussions or collaboration inquiries.
Can AI really predict tomorrow’s stock price? In this hands-on case study, I put a lightweight neural network to the test using none other than NVDA, the tech titan at the heart of the AI revolution. With just five core inputs and zero fluff, this model analyzes years of stock data to forecast next-day prices — delivering insights that are surprisingly sharp, sometimes eerily accurate, and always thought-provoking. If you’re curious about how machine learning can be used to navigate market uncertainty, this article is for you.
Are humans naturally drawn to those who claim to foresee the future?
Astrology, palmistry, crystal balls, clairvoyants, and mystics — all have long fascinated us with their promise of prediction. Today, Artificial Intelligence and Machine Learning (AI/ML) seem to be the modern-day soothsayers, offering insights not through intuition, but through data and mathematics.
With that playful thought in mind, I asked myself: How well can a lightweight neural network forecast tomorrow’s stock price? In this article, I build a simple, no-frills model to predict NVDA’s next-day price — using only essential features and avoiding any complex manipulations
NVDA has captured the imagination of those driving the AI revolution, largely because its GPU chips are the backbone of modern AI/ML models. So, testing my neural network on NVDA’s price movement felt like a fitting experiment — whether the model forecasts accurately or not.
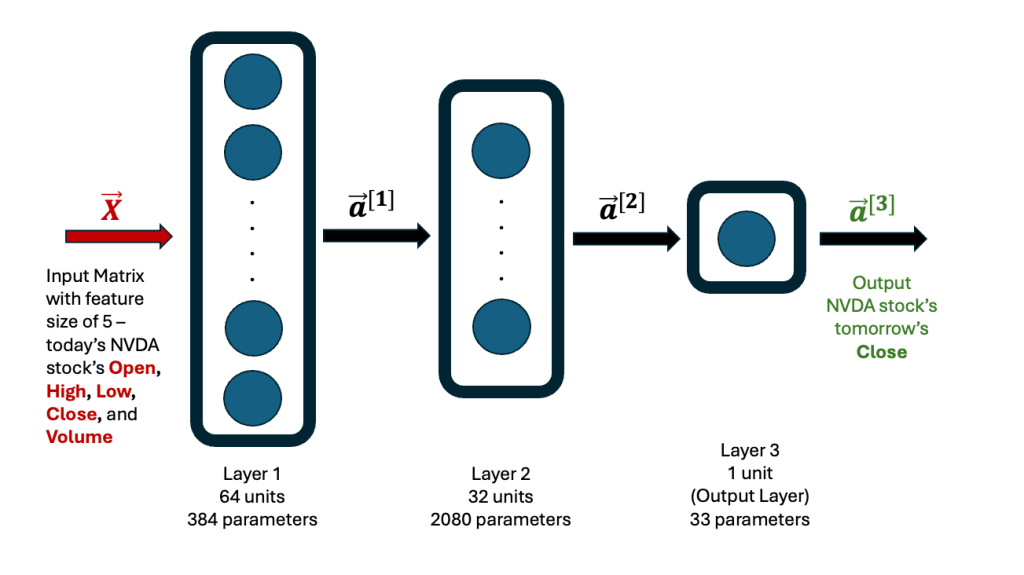
My neural network model takes in just 5 features per data point — the stock’s end-of-day Open, High, Low, Close, and Volume — to predict tomorrow’s Close price.
For training, I used NVDA’s stock data from January 1, 2020, to December 31, 2024 — a five-year period that includes 1,258 trading days. The target variable is the known next day’s Close price. The core idea was simple: Given today’s stock metrics for NVDA, can we predict tomorrow’s Close price?
The basic architecture of the neural network is a schema I’ve used many times before, and I’ve shared it here for clarity.
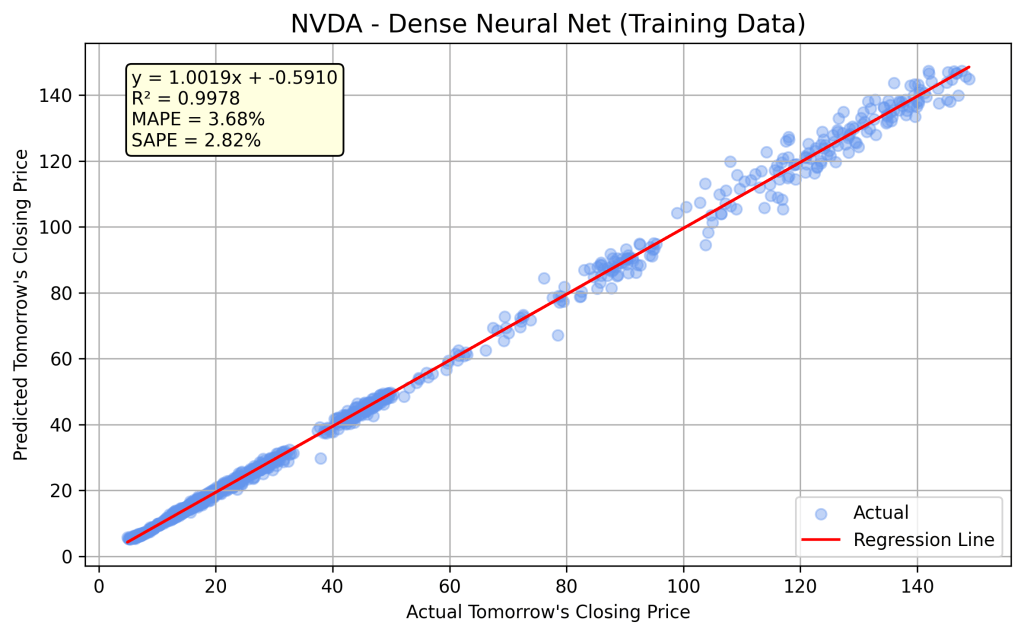
After training, the model learns all its weights and biases, totaling 2,497 parameters. It’s always a good idea to validate predictions made by a newly developed model — by running it on the training data and comparing the results with actual historical data. The graph below illustrates this comparison. The linear regression fit between the actual and predicted Close prices is excellent (R² = 0.9978). MAPE refers to the Mean Absolute Percentage Error, while SAPE is the Standard Deviation of the Percentage Error.
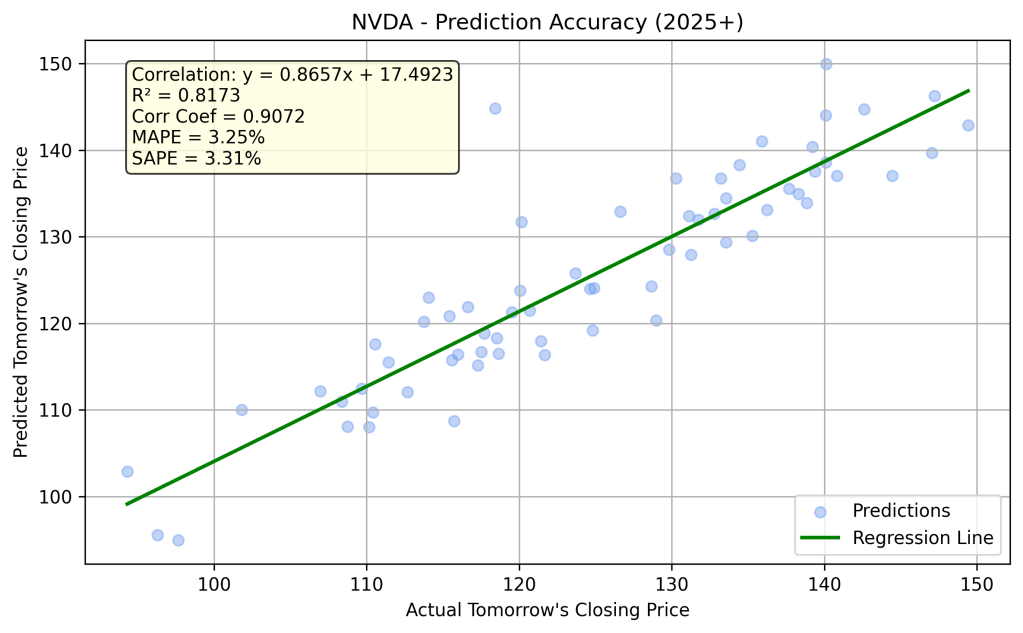
The trained model is now ready to predict NVDA’s closing price for the next trading day, based on today’s end-of-day data. I ran the model for every trading day in 2025, up to the date of writing this article: April 9, 2025 (using the known Close from April 8, 2025). The linear relationship between the actual and predicted Close prices for this period is shown in the following chart.
Even though the percentage error swings wildly in 2025, we can still derive valuable insights from this lightweight neural network model by considering the MAPE bounds. For example, on March 28, 2025, the actual Close was $109.67, while the predicted Close was $113.11, resulting in a -3.14% error. However, based on all 2025 predictions to date, we know that the Mean Absolute Percentage Error (MAPE) is 3.25%. Using this as a guide for lower and upper bounds, the predicted Close range spans from $109.47 to $116.76.
We observe that the actual Close falls within these bounds. I strongly recommend reviewing the current table from the live implementation to make your own observations and draw conclusions.
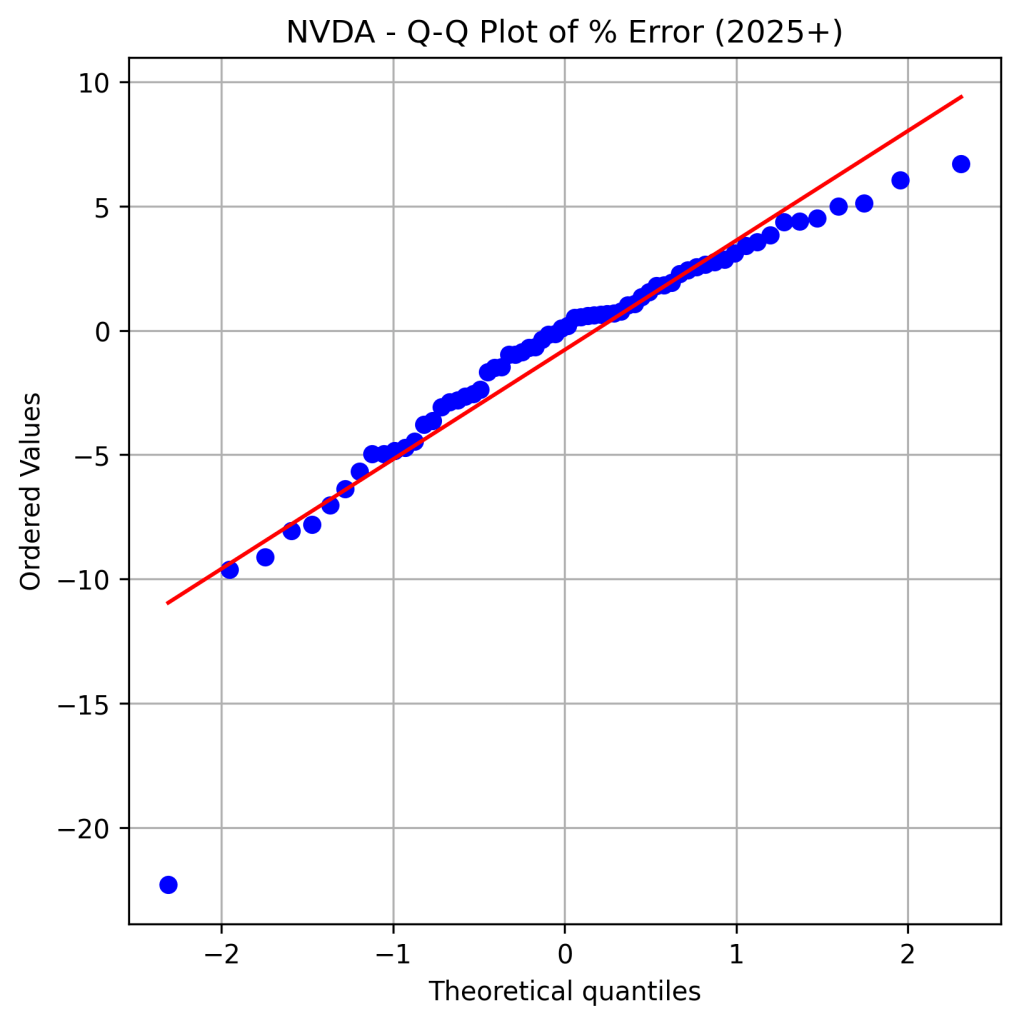
I was also curious to examine the distribution of the percentage error — specifically, whether it follows a normal distribution. The Shapiro-Wilk test (p-value = 0.0000) suggests that the distribution is not normal, while the Kolmogorov-Smirnov (K-S) test (p-value = 0.2716) suggests that it may be approximately normal. The data also exhibits left skewness and is leptokurtic. The histogram and Q-Q plot of the percentage error are shared below.
Another way to visualize the variation between the actual and predicted Close prices in 2025 is by examining the time series price plot, shown below.
Closing Thoughts …
Technical traders rely heavily on chart-based tools to guide their trades — support and resistance levels, moving averages, exponential trends, momentum indicators like RSI and MACD, and hundreds of other technical metrics. While these tools help in identifying trading opportunities at specific points in time, they don’t predict where a stock will close at the end of the trading day. In that sense, their estimates may be no better than the guess of a novice trader.
The average U.S. investor isn’t necessarily a technical day trader or an institutional analyst. And no matter how experienced a trader is, everyone is blind to the net market sentiment of the day. As the saying goes, the market discounts everything — it reacts to macroeconomic shifts, news cycles, political developments, and human emotion. Capturing all that in a forecast is close to impossible.
That’s where neural network-based machine learning models step in. By training on historical data, these models take a more mathematical and algorithmic approach — offering a glimpse into what might lie ahead. While not perfect, they represent a step in the right direction. My own lightweight model, though simple, performs remarkably well on most days. When it doesn’t, it signals that the model likely needs more input features.
To improve predictive power, we can expand the feature set beyond the five core inputs (Open, High, Low, Close, Volume). Additions like percentage return, moving averages (SMA/EMA), rolling volume, RSI, MACD, and others can enhance the model’s ability to interpret market behavior more effectively.
What excites me most is the democratization of this technology. Models like this one can help level the playing field between everyday investors and institutional giants. I foresee a future where companies emerge to build accessible, intelligent trading tools for the average person — tools that were once reserved for Wall Street.
I invite you to explore and follow the live implementation of this model. Observe how its predictions play out in real time. My personal belief is that neural networks hold immense potential in stock prediction — and we’re only just getting started.
Update (May 2025): Since publishing this article, I have deployed a more advanced neural network model that forecasts next-day closing prices for five major stocks (AAPL, GOOGL, MSFT, NVDA, TSLA). The model runs daily and is hosted on a custom FastAPI and NGINX platform at MLPowersAI Stock Prediction.
Disclaimer
The information provided in this article and through the linked prediction model is for educational and informational purposes only. It does not constitute financial, investment, or trading advice, and should not be relied upon as such.
Any decisions made based on the model’s output are solely at the user’s own risk. I make no guarantees regarding the accuracy, completeness, or reliability of the predictions. I am not responsible for any financial losses or gains resulting from the use of this model.
Always consult with a licensed financial advisor before making any investment decisions.
In every factory, industrial operation, and chemical plant, vast amounts of process data are continuously recorded. Yet most of it remains unused, buried in digital archives. What if we could bring this hidden goldmine to life and transform it into a powerful tool for process optimization, cost reduction, and predictive decision-making? AI and machine learning (ML) are revolutionizing industries by turning raw data into actionable insights. From predicting product quality in real-time to optimizing chemical reactions, AI-driven process modeling is not just the future. It is ready to be implemented today.
In this article, I will explore how historical process data can be extracted, neural networks can be trained, and AI models can be deployed to provide instant and accurate predictions. These technologies will help industries operate smarter, faster, and more efficiently than ever before.
How many years of industrial process data are sitting idle on your company’s servers? It’s time to unleash it—because, with AI, it’s a goldmine.
I personally know of billion-dollar companies that have decades of process data collecting dust. Manufacturing firms have been diligently logging process data through automated DCS (Distributed Control Systems) and PLC (Programmable Logic Controller) systems at millisecond intervals—or even smaller—since the 1980s. With advancements in chip technology, data collection has only become more efficient and cost-effective. Leading automation companies such as Siemens (Simatic PCS 7), Yokogawa (Centum VP), ABB (800xA), Honeywell (Experion), Rockwell Automation (PlantPAx), Schneider Electric (Foxboro), and Emerson (Delta V) have been at the forefront of industrial data and process automation. As a result, massive repositories of historical process data exist within organizations—untapped and underutilized.
Every manufacturing process involves inputs (raw materials and energy) and outputs (products). During processing, variables such as temperature, pressure, motor speeds, energy consumption, byproducts, and chemical properties are continuously logged. Final product metrics—such as yield and purity—are checked for quality control, generating additional data. Depending on the complexity of the process, these parameters can range from just a handful to hundreds or even thousands.
A simple analogy: consider the manufacturing of canned soup. Process variables might include ingredient weights, chunk size distribution, flavoring amounts, cooking temperature and pressure profiles, stirring speed, moisture loss, and can-filling rates. The outputs could be both numerical (batch weight, yield, calories per serving) and categorical (taste quality, consistency ratings). This pattern repeats across industries—whether in chemical plants, refineries, semiconductor manufacturing, pharmaceuticals, food processing, polymers, cosmetics, power generation, or electronics—every operation has a wealth of process data waiting to be explored.
For companies, revenue is driven by product sales. Those that consistently produce high-quality products thrive in the marketplace. Profitability improves when sales increase and when cost of goods sold (COGS) and operational inefficiencies are reduced. Process data can be leveraged to minimize product rejects, optimize yield, and enhance quality—directly impacting the bottom line.
How can AI help?
The answer is simple: AI can process vast amounts of historical data and predict product quality and performance based on input parameters—instantly and with remarkable accuracy.
A Real-Life Manufacturing Scenario
Imagine you’re the VP of Manufacturing at a pharmaceutical company that produces a critical cancer drug—a major revenue driver. You’ve been producing this drug for seven years, ensuring a steady supply to patients worldwide.
Today, a new batch has just finished production. It will take a week for quality testing before final approval. However, a power disruption occurred during the run, requiring process adjustments and minor parts replacements. The process was completed as planned, and all critical data was logged. Now, you wait. If the batch fails quality control a week later, it must be discarded, setting you back another 40 days due to production and scheduling delays.
Wouldn’t it be invaluable if you could predict, on the same day, whether the batch would pass or fail? AI can make this possible. By training machine learning models on historical process data and batch outcomes, we can build predictive systems that offer near-instantaneous quality assessments—saving time, money, and resources.
Case Study: CSTR Surrogate AI/ML Model
To illustrate this concept, let’s consider a Continuous Stirred Tank Reactor (CSTR).
The system consists of a feed stream (A) entering a reactor, where it undergoes an irreversible chemical transformation to product (B), and both the unreacted feed (A) and product (B) exit the reactor.
The process inputs are the feed flow rate F (L/min), concentration CA_in (mol/L), and temperature T_in (K, Kelvin).
The process outputs of interest are the exit stream temperature, T_ss (K) and the concentration of unreacted (A), CA_ss (K). Knowing CA_ss is equivalent to knowing the concentration of (B), since the two are related through a straight forward mass balance.
The residence time in the CSTR is designed such that the output has reached steady state conditions. The exit flow rate is the same as the input feed flow rate, since it is a continuous and not a batch reactor.
Generating Data for AI Training
To develop an AI/ML model we would need training data. We could do many experiments and gather the data, in lieu of historical data. However, this CSTR illustration was chosen, since we can generate the output parameters through simulation. Further, this problem has an analytical steady state solution, which can be used for further accuracy comparisons. The focus of this article is not to illustrate the mathematics behind this problem, and therefore, this delegated to a brief note at the end.
When historical data has not been collated from real industrial processes, or if it is unavailable, computer simulations can be run to estimate the output variables for specified input variables. There are more than 50 industrial strength process simulation packages in the market, and some of the popular ones are – Aspen Plus / Aspen HYSYS, CHEMCAD, gPROMS, DWSIM, COMSOL Multiphysics, ANSYS Fluent, ProSim, and Simulink (MATLAB).
Depending on the complexity of the process, the simulation software can take anywhere from minutes, to hours, or even days to generate a single simulation output. When time is a constraint, AI/ML models can serve as a powerful surrogate. Their prediction speeds are orders of magnitude faster than traditional simulation. The only caveat is that the quality of the training data must be good enough to represent the real world historical data closely.
As explained in the brief note in the CSTR Mathematical Model section below, this illustration has the advantage of generating very reliable outputs, for any given set of input conditions. For developing the training set, the input variables were varied in the following ranges.
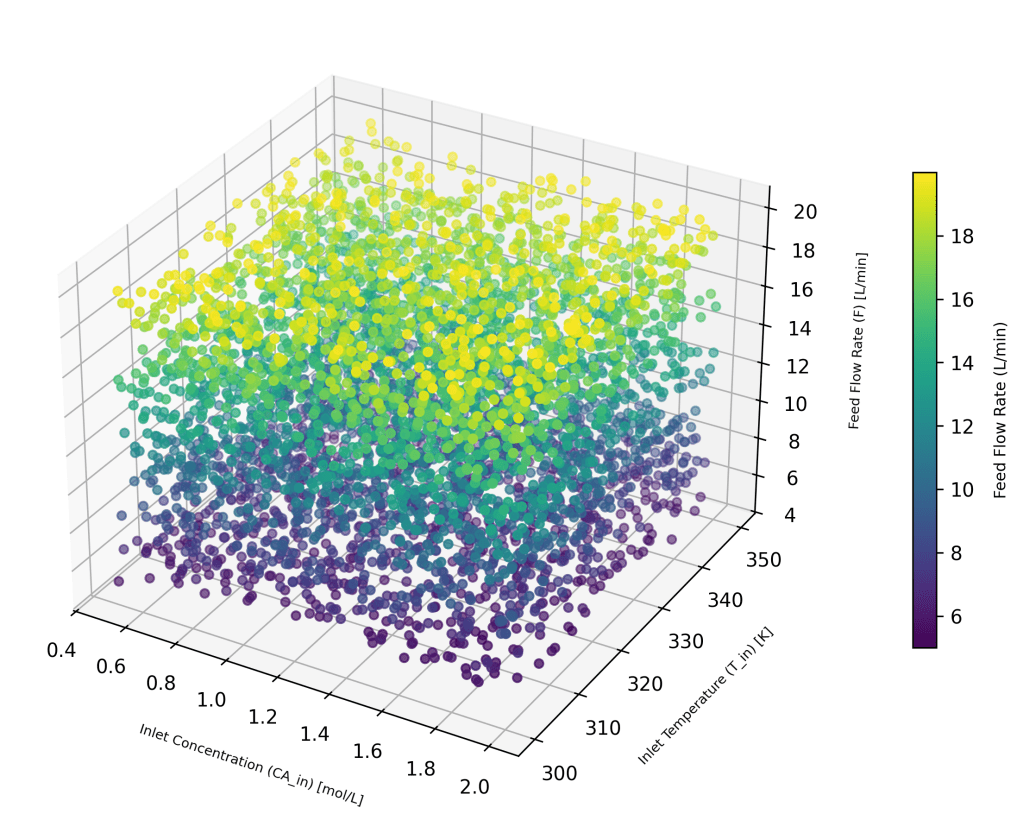
CA_in = 0.5 – 2.0 mol/L
T_in = 300 – 350 K (27 – 77 C)
F = 5 – 20 L/min
Each of the training sets have these 3 input variables. 5000 random feature sets (X) were generated using a uniform distribution, and the 3D plot shows the variations.
For training the AI/ML model 80% of these feature sets were selected at random and used, while for testing 20% were used as the test set. The corresponding output variables, Y, (CA_ss, T_ss) were numerically calculated for each off the 5000 input feature sets, and were used for the respective training and testing.
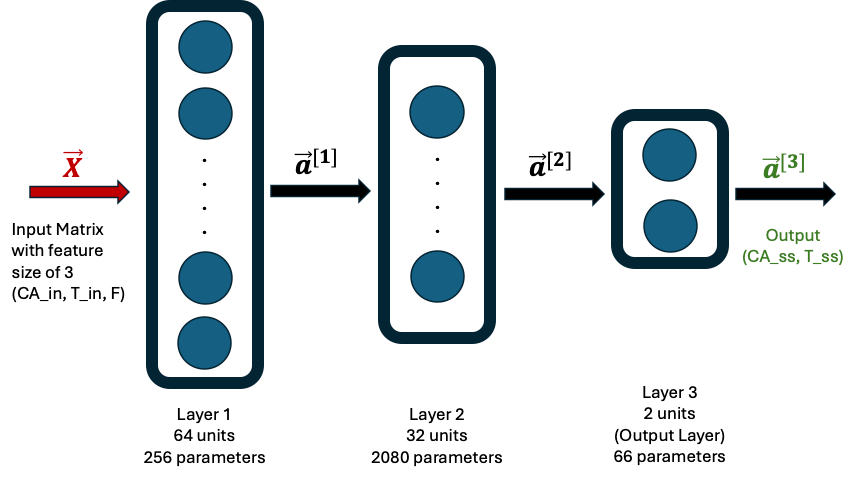
ML Neural Network Model
The ML model consisted of a Neural Network (NN) with 2 hidden layers and one output layer as follows. The first hidden layer had 64 neurons and the second one had 32 neurons. The final output layer had 2 neurons. The ReLU activation was used for the hidden layers and a linear activation for the output layer. The loss function used was mean-squared-error.
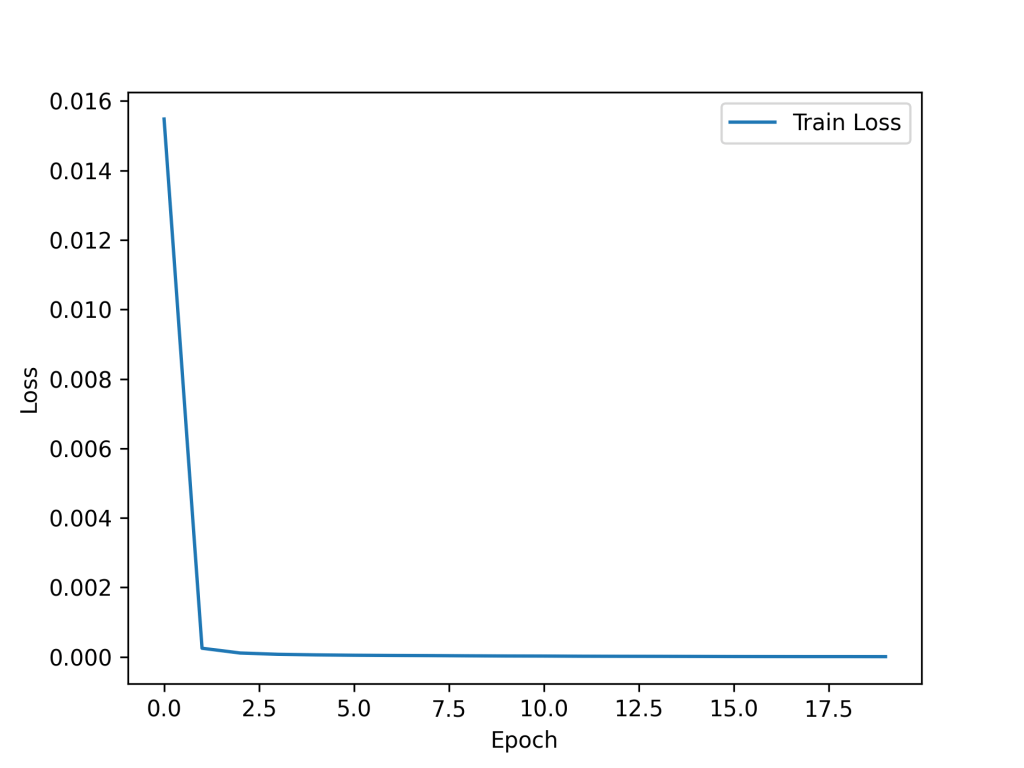
The model was trained on the training set for 20 epochs and showed rapid convergence. The loss vs epochs is presented here. The final loss was near zero (~10-6).
After training the NN model, the Test Set was run. It yielded a Test Loss of zero (rounded off to 4 decimal places) and a Test MAE (mean average error) of 0.0025. The model has performed very nicely on the Test Set.
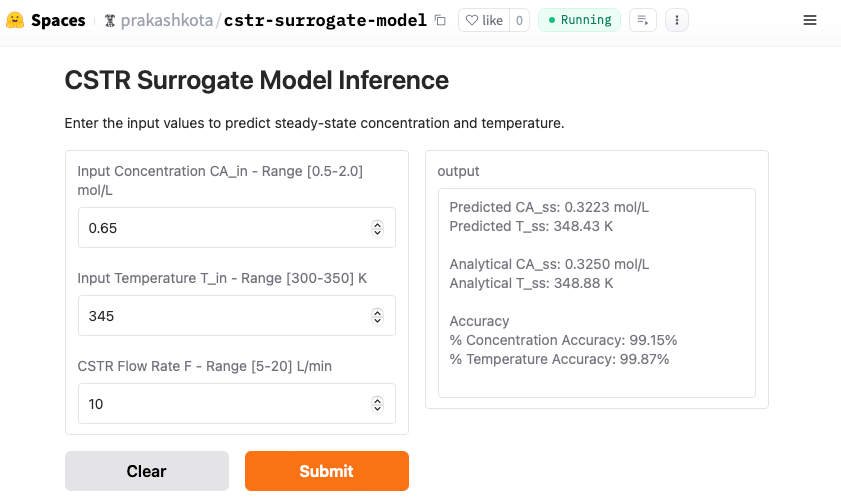
An actual output (screen shot) from a sample inference is shown here for input values which are within the range of the training and test sets. Both outputs (CA_ss and T_ss) are over 99% accurate.
However, this might not be all that surprising, considering the training set—comprising 4,000 feature sets (80% of 5,000)—covered a wide range of possibilities. Our result could simply be close to one of those existing data points. But what happens when we push the boundaries? My response to that would be to test a feature set where some values fall outside the training range.
For instance, in our dataset, the temperature varied between 300–350 K. What if we increase it by 10% beyond the upper limit, setting it at 385 K? Plugging this into the model, we still get an inference with over 99% accuracy! The predicted steady-state temperature (T_ss) is 385.35 K, compared to the analytical solution of 388.88 K, yielding an accuracy of 99.09%. A screenshot of the results is shared below.
Summary
I’m convinced that AI/ML has remarkable power to predict real-world scenarios with unmatched speed and accuracy. I hope this article has convinced you too. Within every company lies a hidden treasure trove of historical process data—an untapped goldmine waiting to be leveraged. When this data is extracted, cleaned, and harnessed to train a custom ML model, it transforms from an archive of past events into a powerful tool for the future.
The potential benefits are immense: vastly improved process efficiency, enhanced product quality, smarter process optimization, reduced downtime, better scheduling and planning, elimination of guesswork, and increased profitability. Incorporating ML into industrial processes requires effort—models must be carefully designed, trained, and deployed for real-time inference. While there may be cases where a single ML model can serve multiple organizations, we are still in the early stages of AI/ML adoption in process industries, and these scalable use cases are yet to be fully explored.
Right now, the opportunity is massive. The companies that act today—dusting off their historical data, building custom AI models, and integrating ML into their operations—will set the standard and lead their industries into the future. The question is: Will your company be among them?
Read this section only if you like math and want the details!
The mass and energy balance on the CSTR yield the following equations, which give the variation of concentration for the reacting species (A) and the fluid temperature (T) as a function of time (t).
and are the exit concentration of A and fluid temperature . Since the residence time is long enough to reach steady state, for this irreversible reaction,
CA_ss
T_ss
The following model parameters have been taken to be a constant for all the simulated runs and analytical calculations. There is no requirement to have physical properties to be constant, since they could be allowed to vary with temperature. However, for this simulation they have been held constant.
100 L (tank volume)
-50,000 J/mol (heat of exothermic reaction)
1 Kg/L (fluid density)
4184 J/Kg.K (fluid specific heat capacity)
The irreversible reaction for species (A) going to (B) is modeled as a first order rate equation, with the rate constant 0.1 min-1, and where is the reaction rate (mol/L.min).
I have used a mix of SI and common units. However, when taken together in the equation, the combined units work consistently.
The analytical solution is easy to calculate and can be done by setting the time derivatives to zero and solving for the concentration and temperature. These are provided here for completeness.
CA_ss
T_ss = T_in –
To simulate the training set, we can calculate CA_ss and T_ss from the above equations. I have computed CA_ss and T_ss by solving the system of ordinary differential equations using scipy.integrate.solve_ivp, which is an adaptive-step solver in SciPy. The steady state values were taken as the dependent variable values after a lapse time of 50 minutes. These values would vary slightly from analytical values. But, they provide small variations, just like in real processes due to inherent fluctuations.
Medical misdiagnoses continue to be a significant concern worldwide, often leading to unnecessary complications and preventable deaths. According to the World Health Organization (WHO), at least 5% of adults in the U.S. experience a diagnostic error annually. The impact on a global scale is even more alarming. Despite rapid advancements in Artificial Intelligence (AI) and Machine Learning (ML), adoption in clinical settings remains limited. Many healthcare professionals remain skeptical, with only 3% of European healthcare organizations expressing trust in AI-enabled diagnostics. This blog explores the application of Neural Networks in breast cancer detection using the Wisconsin Breast Cancer Dataset. It examines how TensorFlow based models can improve diagnostic accuracy and assesses the potential of AI-driven systems in medical practice
Have you felt rushed in a doctor’s office? Have you ever left an appointment wondering if the doctor thoroughly reviewed your blood test results and other relevant information? Have you doubted the Doctor’s opinion? You are not alone!
In a 2019 World Health Organization (WHO)article, WHO states that their research shows that at least 5% of adults in the United States experience a diagnostic error each year in outpatient settings. In a 2023 article in BMJ, the authors state that there are 2.59 million missed diagnoses in the US, accounting for 371,000 deaths and 424,000 disabilities. These numbers are for only the false negative errors. When considered on a global scale, the numbers are staggering.
Whatever may be the reason for the errors in medical diagnosis, it’s obvious that these numbers must come down. Most doctors that I have met for a professional consultation, for myself or my family members, have advised me not to ‘Google’ medical conditions. At the same time, they do not have enough of time or patience to explain the condition. I can’t blame them, considering their patient load and time constraints.
The enormous interest in AI and Machine Learning, in all walks of life, is a tool that doctors should be using daily to minimize errors in medical diagnosis. I had assumed that this is happening at a rapid pace. But I was so wrong on this. In a 2022 article in the Frontiers in Medicine, the authors conclude that from their survey of medical professionals in 39 countries, 38% had awareness of clinical AI, but that 53% lacked basic knowledge of clinical AI. Their work also revealed that 68% of doctors disagreed that AI would become a surrogate physician, but they believed that AI should assist in clinical decision making. In a 2024 online summary, it is mentioned that 42% of healthcare organizations in the European Union were currently using AI technologies for disease diagnosis, but that only 3% trusted AI-enabled decisions in disease diagnostics. These pieces of information only indicate that the adoption of AI for disease diagnosis is under suspicion by the professionals. If anything, the adoption is slow, though the advancement in AI and Machine Learning has been very rapid. There is a trust and acceptance deficit when it comes to AI/ML in medical practice. Integration of AI/ML into clinical workflows would be the next big challenge. Finally, regulatory approvals would be a barrier to AI/ML implementation in medical establishments. But these hurdles will be overcome in due time, hopefully sooner rather than later.
I like to work on small cases when confronted with big questions such as this one. I’ll share with you a case that is based on Breast Cancer. American Cancer Society estimates that Approximately 1 in 8 women in the US (13.1%) will be diagnosed with invasive breast cancer, and 1 in 43 (2.3%) will die from the disease. Breastcancer.org estimates that approximately 310,720 women are expected to be diagnosed with invasive breast cancer annually in the US. Stopbreastcancer.org estimates that the mortality rate in the US is about 42,170 annually. WHO reports that in 2022 approximately 2.3 million women worldwide were diagnosed with breast cancer, accounting for 11.6% of all cancer cases globally. Further, it reported 670,000 breast cancer related deaths in 2022.
Doctors use a variety of techniques to detect breast cancer – mammography, breast ultrasound, PET scans, DNA sequencing and biopsies. A biopsy, which is a small extraction of a physical sample for microscope analysis, is a standard investigation tool. The investigations are performed by pathologists. The output from this analysis are measurements and metrics that capture features, giving the pathologists a means to reliably diagnose whether the lesions are malignant or benign.
A reputed biopsy database, based on the fine needle aspiration technique, is the Diagnostic Wisconsin Breast Cancer Database. It contains data for 569 patient biopsies, with each data set having 30 measurement features, shown here.
The header contains 32 categories, but the first column is the patient ID and the second column is the actual diagnosis, M is for malignant and B is for benign. Excluding this header and the first 2 columns, the data is a matrix of size (569,30). With 30 pieces of input data for a single biopsy for a patient, it seems daunting for a pathologist to look at all of them, in its entirety, to diagnose whether a biopsy is cancerous or not. For example, the large input feature set for the first patient, based on actual data in the data set, is shown here to give you an idea of the volume of data to consider before a diagnosis.
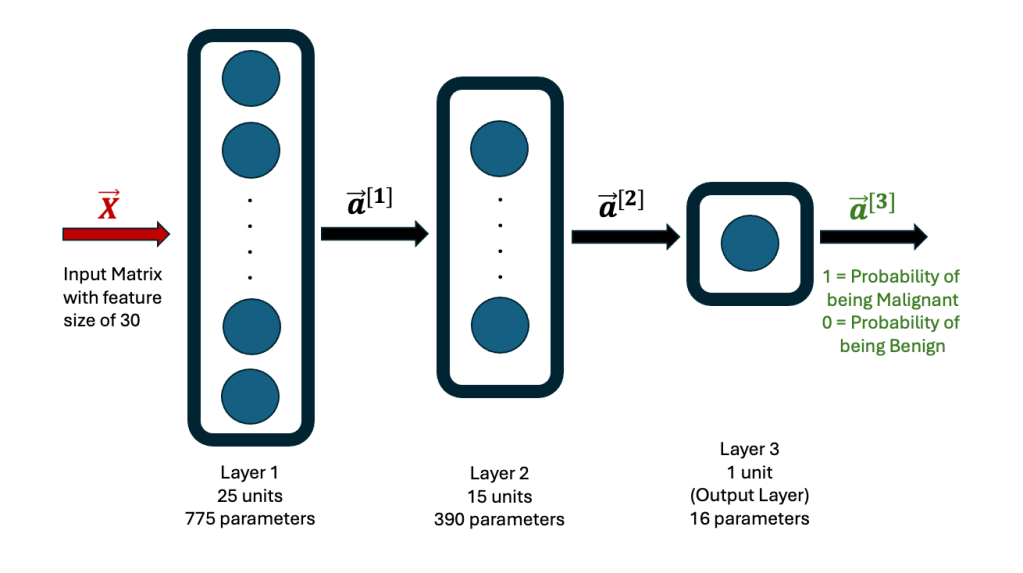
Using this dataset, a Neural Network algorithm for Structured Machine Learning was created, using TensorFlow. The Jupyter Notebook Python code is on Github. The Neural Network consists of 3 hidden layers, the first one with 25 neurons (units), the second one with 15 neurons and the third one with 1 neuron. The first two layers use the ReLU function, while the last one uses the Sigmoid function. The architecture is shown here.
Rows 26 to 569 in the breast cancer data set were used as the Training set, while the first 25 rows were used as the Test set. The former is used to establish the weights and biases in each neuron in the network. The final output is either a 1 or 0, with 1 indicating that the data corresponds to a malignant diagnosis, while a 0 corresponds to a benign diagnosis.
After running the Neural Network code, the model was used to predict outputs for the entire Training set. Since the Training set contains the actual diagnosis (1 = M = Malignant) and (0 = B = Benign), it can be compared to the predicted output, to compute the accuracy of the Neural Network model. The model predicts a 99.26% accuracy. The predicted versus the actual output for the first 25 rows of the Training set is shown here. For the 15th row, the model predicts the outcome as 0, while the actual outcome is 1. Hence, the overall accuracy over the entire Training set is less than 100%, but still remarkable at 99.26%.
Next, the same model is used to predict the outcome for the Test set. The model has never seen this Test set before. It is equivalent to new patient data coming from the field. The prediction from the model for the Test set shows an accuracy of 100%! For comparison, the entire 26 rows of the predicted versus actual outcomes for the Test set is shown here.
These results are stunning. It emphatically shows the power of Machine Learning algorithms. For this specific case study, with a Training set of 543 patient records, it is possible to predict the cancer diagnosis for any new patient record, with an extremely high degree of accuracy.
With the number of tests that doctors ask patients to go through, hundreds of data values are generated. To make sense of all these data values, data analytics is required, rather than reliance on a cursory glance by a doctor. Neural Networks and Supervised Machine Learning are powerful AI tools that will benefit the patient today. AI can be applied to any disease diagnosis, for which raw data exists. Its adoption for reliable medical diagnosis is the need of the hour.
For those interested, the breast cancer dataset can also be analyzed using a Logistics Regression algorithm, using the Scikit-learn package. This code has also been provided on Github. The results are comparable to the Neural Network algorithm. Another small note – the TensorFlow package is one among several options available for writing Neural Networks code. Other choices are PyTorch (Meta), JAX (Google), MXNet (Apache) and CNTK (Microsoft).




 were set at 0.8, 1.0, 0.5, 0.6, 0.4, and 0.3 respectively.
were set at 0.8, 1.0, 0.5, 0.6, 0.4, and 0.3 respectively.  are the activation energy (0.5 eV) and universal gas constant (8.617×10-5 eV/K) respectively.
are the activation energy (0.5 eV) and universal gas constant (8.617×10-5 eV/K) respectively.  are the controllable process variables – plasma power (W), bias voltage (V), pressure (mTorr), flow rates of gases (sccm) and temperature (C, converted to K) respectively.
are the controllable process variables – plasma power (W), bias voltage (V), pressure (mTorr), flow rates of gases (sccm) and temperature (C, converted to K) respectively. 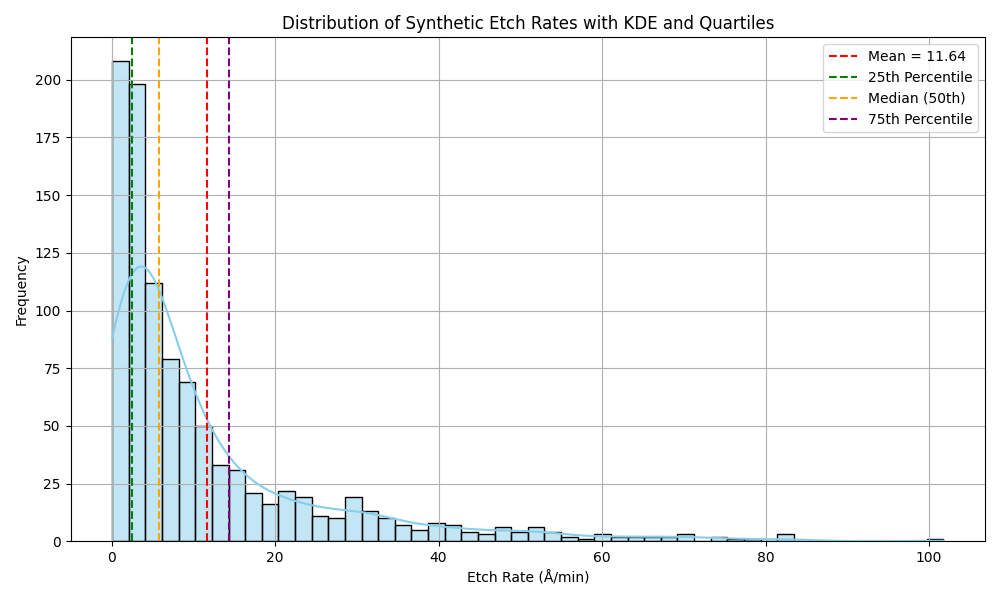











 and
and  are the exit concentration of A and fluid temperature
are the exit concentration of A and fluid temperature 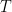 . Since the residence time is long enough to reach steady state, for this irreversible reaction,
. Since the residence time is long enough to reach steady state, for this irreversible reaction,  CA_ss
CA_ss T_ss
T_ss 100 L (tank volume)
100 L (tank volume) -50,000 J/mol (heat of exothermic reaction)
-50,000 J/mol (heat of exothermic reaction) 1 Kg/L (fluid density)
1 Kg/L (fluid density) 4184 J/Kg.K (fluid specific heat capacity)
4184 J/Kg.K (fluid specific heat capacity) 0.1 min-1, and where
0.1 min-1, and where  is the reaction rate (mol/L.min).
is the reaction rate (mol/L.min).