I am pleased to share that my article on applying Business Machine Learning (BML) to pharmaceutical cost estimation has been published in Chemical Engineering Progress (CEP), the flagship magazine of AIChE. The article explores how BML can uncover hidden efficiencies in pharmaceutical manufacturing economics.
In every factory, industrial operation, and chemical plant, vast amounts of process data are continuously recorded. Yet most of it remains unused, buried in digital archives. What if we could bring this hidden goldmine to life and transform it into a powerful tool for process optimization, cost reduction, and predictive decision-making? AI and machine learning (ML) are revolutionizing industries by turning raw data into actionable insights. From predicting product quality in real-time to optimizing chemical reactions, AI-driven process modeling is not just the future. It is ready to be implemented today.
In this article, I will explore how historical process data can be extracted, neural networks can be trained, and AI models can be deployed to provide instant and accurate predictions. These technologies will help industries operate smarter, faster, and more efficiently than ever before.
How many years of industrial process data are sitting idle on your company’s servers? It’s time to unleash it—because, with AI, it’s a goldmine.
I personally know of billion-dollar companies that have decades of process data collecting dust. Manufacturing firms have been diligently logging process data through automated DCS (Distributed Control Systems) and PLC (Programmable Logic Controller) systems at millisecond intervals—or even smaller—since the 1980s. With advancements in chip technology, data collection has only become more efficient and cost-effective. Leading automation companies such as Siemens (Simatic PCS 7), Yokogawa (Centum VP), ABB (800xA), Honeywell (Experion), Rockwell Automation (PlantPAx), Schneider Electric (Foxboro), and Emerson (Delta V) have been at the forefront of industrial data and process automation. As a result, massive repositories of historical process data exist within organizations—untapped and underutilized.
Every manufacturing process involves inputs (raw materials and energy) and outputs (products). During processing, variables such as temperature, pressure, motor speeds, energy consumption, byproducts, and chemical properties are continuously logged. Final product metrics—such as yield and purity—are checked for quality control, generating additional data. Depending on the complexity of the process, these parameters can range from just a handful to hundreds or even thousands.
A simple analogy: consider the manufacturing of canned soup. Process variables might include ingredient weights, chunk size distribution, flavoring amounts, cooking temperature and pressure profiles, stirring speed, moisture loss, and can-filling rates. The outputs could be both numerical (batch weight, yield, calories per serving) and categorical (taste quality, consistency ratings). This pattern repeats across industries—whether in chemical plants, refineries, semiconductor manufacturing, pharmaceuticals, food processing, polymers, cosmetics, power generation, or electronics—every operation has a wealth of process data waiting to be explored.
For companies, revenue is driven by product sales. Those that consistently produce high-quality products thrive in the marketplace. Profitability improves when sales increase and when cost of goods sold (COGS) and operational inefficiencies are reduced. Process data can be leveraged to minimize product rejects, optimize yield, and enhance quality—directly impacting the bottom line.
How can AI help?
The answer is simple: AI can process vast amounts of historical data and predict product quality and performance based on input parameters—instantly and with remarkable accuracy.
A Real-Life Manufacturing Scenario
Imagine you’re the VP of Manufacturing at a pharmaceutical company that produces a critical cancer drug—a major revenue driver. You’ve been producing this drug for seven years, ensuring a steady supply to patients worldwide.
Today, a new batch has just finished production. It will take a week for quality testing before final approval. However, a power disruption occurred during the run, requiring process adjustments and minor parts replacements. The process was completed as planned, and all critical data was logged. Now, you wait. If the batch fails quality control a week later, it must be discarded, setting you back another 40 days due to production and scheduling delays.
Wouldn’t it be invaluable if you could predict, on the same day, whether the batch would pass or fail? AI can make this possible. By training machine learning models on historical process data and batch outcomes, we can build predictive systems that offer near-instantaneous quality assessments—saving time, money, and resources.
Case Study: CSTR Surrogate AI/ML Model
To illustrate this concept, let’s consider a Continuous Stirred Tank Reactor (CSTR).
The system consists of a feed stream (A) entering a reactor, where it undergoes an irreversible chemical transformation to product (B), and both the unreacted feed (A) and product (B) exit the reactor.
The process inputs are the feed flow rate F (L/min), concentration CA_in (mol/L), and temperature T_in (K, Kelvin).
The process outputs of interest are the exit stream temperature, T_ss (K) and the concentration of unreacted (A), CA_ss (K). Knowing CA_ss is equivalent to knowing the concentration of (B), since the two are related through a straight forward mass balance.
The residence time in the CSTR is designed such that the output has reached steady state conditions. The exit flow rate is the same as the input feed flow rate, since it is a continuous and not a batch reactor.
Generating Data for AI Training
To develop an AI/ML model we would need training data. We could do many experiments and gather the data, in lieu of historical data. However, this CSTR illustration was chosen, since we can generate the output parameters through simulation. Further, this problem has an analytical steady state solution, which can be used for further accuracy comparisons. The focus of this article is not to illustrate the mathematics behind this problem, and therefore, this delegated to a brief note at the end.
When historical data has not been collated from real industrial processes, or if it is unavailable, computer simulations can be run to estimate the output variables for specified input variables. There are more than 50 industrial strength process simulation packages in the market, and some of the popular ones are – Aspen Plus / Aspen HYSYS, CHEMCAD, gPROMS, DWSIM, COMSOL Multiphysics, ANSYS Fluent, ProSim, and Simulink (MATLAB).
Depending on the complexity of the process, the simulation software can take anywhere from minutes, to hours, or even days to generate a single simulation output. When time is a constraint, AI/ML models can serve as a powerful surrogate. Their prediction speeds are orders of magnitude faster than traditional simulation. The only caveat is that the quality of the training data must be good enough to represent the real world historical data closely.
As explained in the brief note in the CSTR Mathematical Model section below, this illustration has the advantage of generating very reliable outputs, for any given set of input conditions. For developing the training set, the input variables were varied in the following ranges.
CA_in = 0.5 – 2.0 mol/L
T_in = 300 – 350 K (27 – 77 C)
F = 5 – 20 L/min
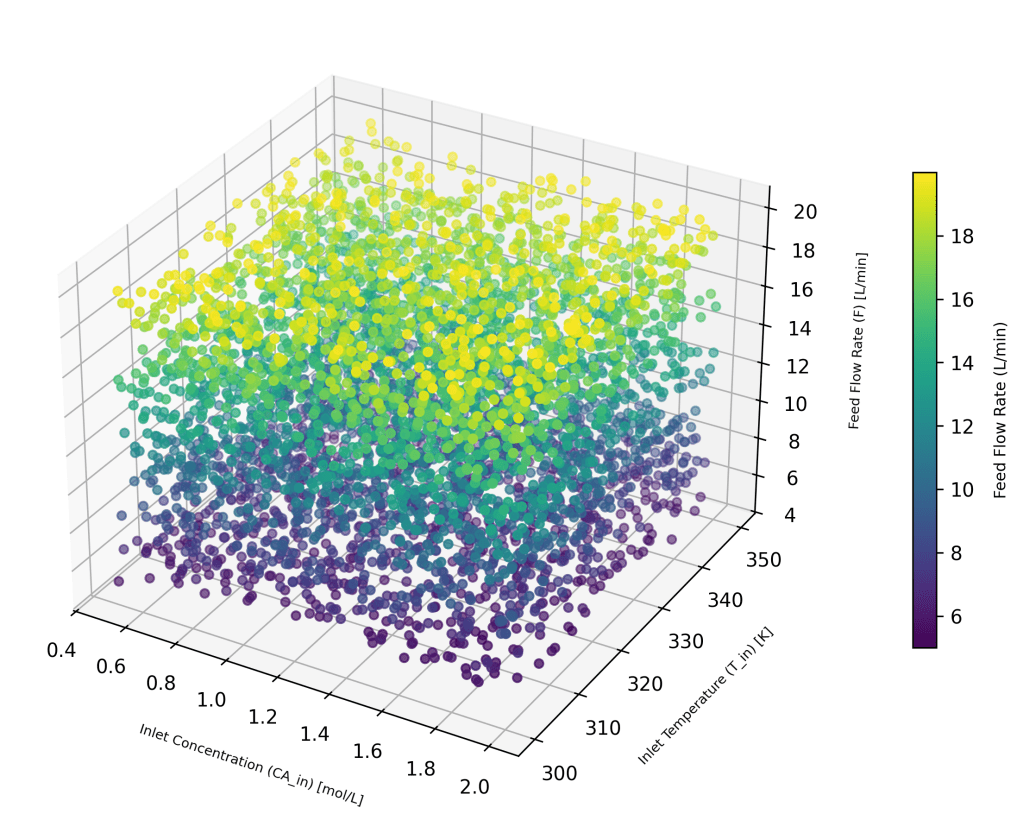
Each of the training sets have these 3 input variables. 5000 random feature sets (X) were generated using a uniform distribution, and the 3D plot shows the variations.
For training the AI/ML model 80% of these feature sets were selected at random and used, while for testing 20% were used as the test set. The corresponding output variables, Y, (CA_ss, T_ss) were numerically calculated for each off the 5000 input feature sets, and were used for the respective training and testing.
ML Neural Network Model
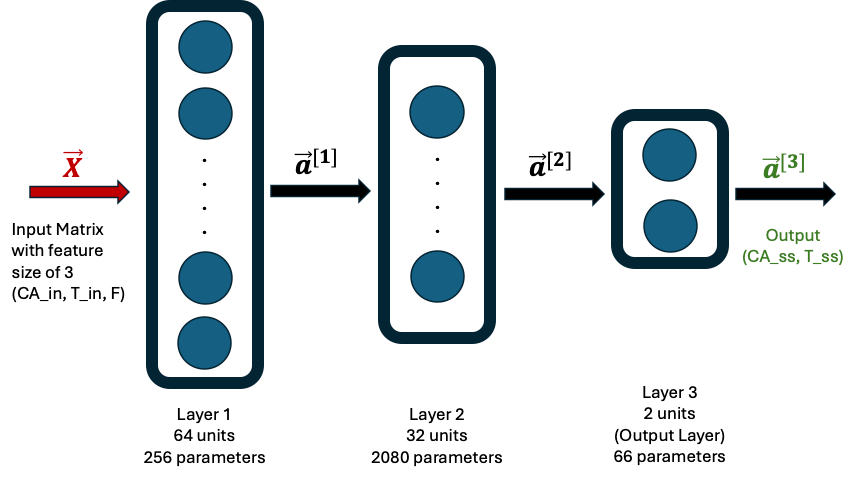
The ML model consisted of a Neural Network (NN) with 2 hidden layers and one output layer as follows. The first hidden layer had 64 neurons and the second one had 32 neurons. The final output layer had 2 neurons. The ReLU activation was used for the hidden layers and a linear activation for the output layer. The loss function used was mean-squared-error.
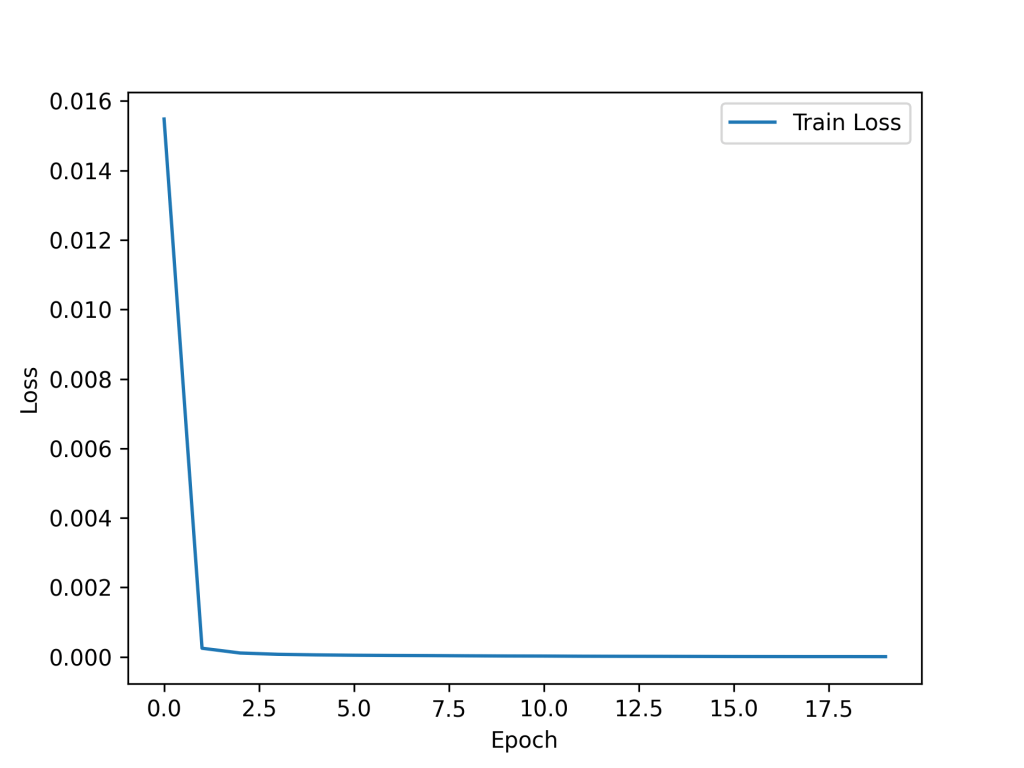
The model was trained on the training set for 20 epochs and showed rapid convergence. The loss vs epochs is presented here. The final loss was near zero (~10-6).
After training the NN model, the Test Set was run. It yielded a Test Loss of zero (rounded off to 4 decimal places) and a Test MAE (mean average error) of 0.0025. The model has performed very nicely on the Test Set.
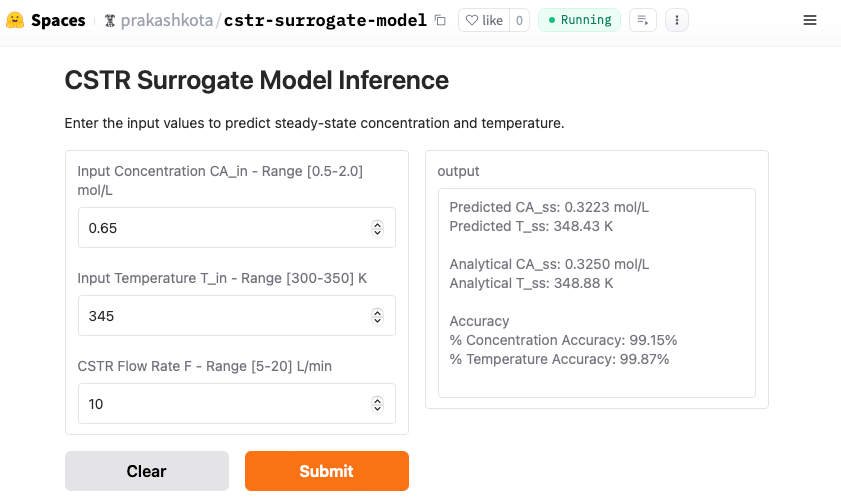
An actual output (screen shot) from a sample inference is shown here for input values which are within the range of the training and test sets. Both outputs (CA_ss and T_ss) are over 99% accurate.
However, this might not be all that surprising, considering the training set—comprising 4,000 feature sets (80% of 5,000)—covered a wide range of possibilities. Our result could simply be close to one of those existing data points. But what happens when we push the boundaries? My response to that would be to test a feature set where some values fall outside the training range.
For instance, in our dataset, the temperature varied between 300–350 K. What if we increase it by 10% beyond the upper limit, setting it at 385 K? Plugging this into the model, we still get an inference with over 99% accuracy! The predicted steady-state temperature (T_ss) is 385.35 K, compared to the analytical solution of 388.88 K, yielding an accuracy of 99.09%. A screenshot of the results is shared below.
Summary
I’m convinced that AI/ML has remarkable power to predict real-world scenarios with unmatched speed and accuracy. I hope this article has convinced you too. Within every company lies a hidden treasure trove of historical process data—an untapped goldmine waiting to be leveraged. When this data is extracted, cleaned, and harnessed to train a custom ML model, it transforms from an archive of past events into a powerful tool for the future.
The potential benefits are immense: vastly improved process efficiency, enhanced product quality, smarter process optimization, reduced downtime, better scheduling and planning, elimination of guesswork, and increased profitability. Incorporating ML into industrial processes requires effort—models must be carefully designed, trained, and deployed for real-time inference. While there may be cases where a single ML model can serve multiple organizations, we are still in the early stages of AI/ML adoption in process industries, and these scalable use cases are yet to be fully explored.
Right now, the opportunity is massive. The companies that act today—dusting off their historical data, building custom AI models, and integrating ML into their operations—will set the standard and lead their industries into the future. The question is: Will your company be among them?
Read this section only if you like math and want the details!
The mass and energy balance on the CSTR yield the following equations, which give the variation of concentration for the reacting species (A) and the fluid temperature (T) as a function of time (t).
and are the exit concentration of A and fluid temperature . Since the residence time is long enough to reach steady state, for this irreversible reaction,
CA_ss
T_ss
The following model parameters have been taken to be a constant for all the simulated runs and analytical calculations. There is no requirement to have physical properties to be constant, since they could be allowed to vary with temperature. However, for this simulation they have been held constant.
100 L (tank volume)
-50,000 J/mol (heat of exothermic reaction)
1 Kg/L (fluid density)
4184 J/Kg.K (fluid specific heat capacity)
The irreversible reaction for species (A) going to (B) is modeled as a first order rate equation, with the rate constant 0.1 min-1, and where is the reaction rate (mol/L.min).
I have used a mix of SI and common units. However, when taken together in the equation, the combined units work consistently.
The analytical solution is easy to calculate and can be done by setting the time derivatives to zero and solving for the concentration and temperature. These are provided here for completeness.
CA_ss
T_ss = T_in –
To simulate the training set, we can calculate CA_ss and T_ss from the above equations. I have computed CA_ss and T_ss by solving the system of ordinary differential equations using scipy.integrate.solve_ivp, which is an adaptive-step solver in SciPy. The steady state values were taken as the dependent variable values after a lapse time of 50 minutes. These values would vary slightly from analytical values. But, they provide small variations, just like in real processes due to inherent fluctuations.








 and
and  are the exit concentration of A and fluid temperature
are the exit concentration of A and fluid temperature 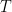 . Since the residence time is long enough to reach steady state, for this irreversible reaction,
. Since the residence time is long enough to reach steady state, for this irreversible reaction,  CA_ss
CA_ss T_ss
T_ss 100 L (tank volume)
100 L (tank volume) -50,000 J/mol (heat of exothermic reaction)
-50,000 J/mol (heat of exothermic reaction) 1 Kg/L (fluid density)
1 Kg/L (fluid density) 4184 J/Kg.K (fluid specific heat capacity)
4184 J/Kg.K (fluid specific heat capacity) 0.1 min-1, and where
0.1 min-1, and where  is the reaction rate (mol/L.min).
is the reaction rate (mol/L.min).


