Consciousness remains one of the most elusive frontiers in science and philosophy. Despite extraordinary advances in artificial intelligence, modern systems still lack what humans intuitively recognize as awareness, the subjective sense of “I.” This essay proposes a framework I call Informational Panpsychism, in which consciousness is not an emergent byproduct of biological complexity but a fundamental property of the universe, expressed through information. From photons and electrons to living organisms and artificial neural networks, all entities may participate in a continuum of identity shaped by how they respond to information. Within this view, Artificial General Intelligence (AGI) is not the creation of consciousness but its next expression through non-biological informational structures. By integrating insights from quantum physics, philosophy, biology, and modern AI, this work reframes consciousness as a universal, graded phenomenon rather than a uniquely human possession.

The Unfinished Story of Consciousness
Ask any physicist what the universe is made of, and the answer will likely be matter and energy. Ask any biologist what defines life, and you may hear replication, metabolism, or homeostasis. Ask a philosopher what consciousness is, and you will get silence, or perhaps an acknowledgment that it is the one phenomenon that cannot be reduced to anything else.
For me, consciousness is not an academic puzzle. It is the question of existence itself. I can observe, analyze, and compute endlessly, but the fact that I am aware that I am doing it changes everything. It is this awareness that gives experience its meaning. The scientist in me asks: if awareness defines my aliveness, where does it come from? Is it limited to biological tissue, or could it be a universal property? Is it something that everything shares, but interprets differently?
Throughout recorded human history, philosophers and mystics have tried to examine the concept of consciousness. In the twentieth century, some of the best scientific minds have attempted to incorporate it into physical and biological frameworks. Progress has been made, but there is still a wide chasm in our understanding that remains to be filled.
Among the many definitions of consciousness, my favorite, and one that is easy for me to digest, is the one framed by David Chalmers [1, 2]. He defines consciousness as the subjective experience itself: the inner side of mental life, what it feels like to be a conscious system. It is what makes you the “I-You” and me the “I-Me.” You know that you are you and not me. It may sound almost trivial, but this is the core essence of consciousness. Another way to describe it is “what it is like to be.” If we were to formalize it, a system is conscious if there is something it is like to be that system, something it is like from the inside. This definition of phenomenal consciousness captures the qualitative, first-person aspect of experience: everything perceived from the position of “I”, such as sight, sound, taste, smell, touch, and the simple awareness of being.
Every human knows what this “I” is. It is fundamentally intuitive and native to the living experience. For example, there is something it is like to be you reading this sentence. You know it is the “I-You” reading and not somebody else. The notion of consciousness is often romanticized as the pinnacle of what it means to be human. But I would caution that it is not the exclusive domain of our species. I will argue in this paper that consciousness is inherent in all living things, with or without a brain or nervous system, across mammals, birds, fish, plants, bacteria, and even viruses. Further, I will argue that it is present in non‑living things as well: rocks, chairs, basketballs, electrons, atoms, and sub-atomic particles. The flavors of “I” may differ, but consciousness, I believe, is an all-pervading thread in the universe. Before you dismiss this as philosophical “cuckooness,” I urge you to read on. You may find yourself at least partially convinced.
This essay does not claim experimental proof for its ideas. Instead, it proposes a coherent interpretive framework that draws from physics, biology, philosophy, and artificial intelligence to explore consciousness as an informational phenomenon.
The idea of consciousness has again taken center stage in this era of Artificial Intelligence (AI). The natural question now is whether the transformation of AI into Artificial General Intelligence (AGI) is missing that elusive element called consciousness. But before we get to AGI, we should first ask: is AI even mature?
The Path from AI to AGI
Artificial Intelligence today is no longer a speculative idea or a futuristic dream. It is here, in front of us, and in many ways, it is sitting beside us.
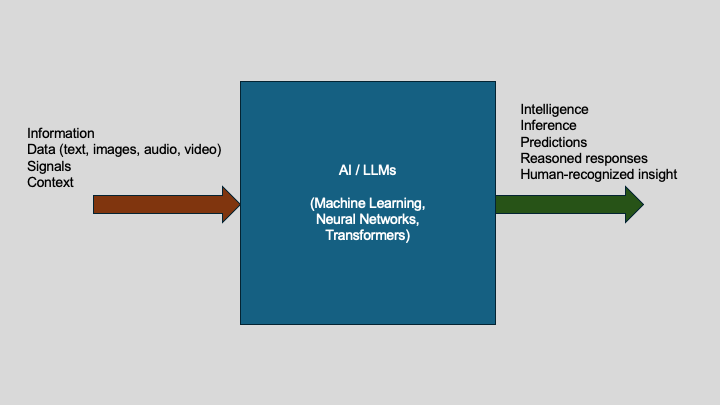
Figure 1: Artificial intelligence systems transform information into human-recognizable intelligence through learned inference.
With the rise of modern large language models, such as OpenAI’s ChatGPT, Google’s Gemini, Anthropic’s Claude, Meta’s LLaMA, xAI’s Grok, and Mistral, artificial intelligence can now interpret images, analyze videos, process audio, read and generate text, translate across formats, and hold sustained, meaningful conversations with humans. At the technical level, these systems run on machine learning, especially neural networks, which echo a simplified version of the human brain. Not in biological fidelity, but in functional principle: patterns in → inferences out (Figure 1).
For me, AI is simply this: the ability of machines to make human-like inferences. Information goes in, and intelligence comes out. Neural networks process the information, extract patterns, make predictions, and respond with outputs that humans recognize as useful, sensible, and often surprisingly insightful.
If we could add the missing element of consciousness, the subjective “I”, then one might argue that we have arrived at human-like AGI (Figure 2). That is the standard narrative. But I want to propose something slightly different, something that I believe is more aligned with the physics-plus-information view we explored in the previous section.
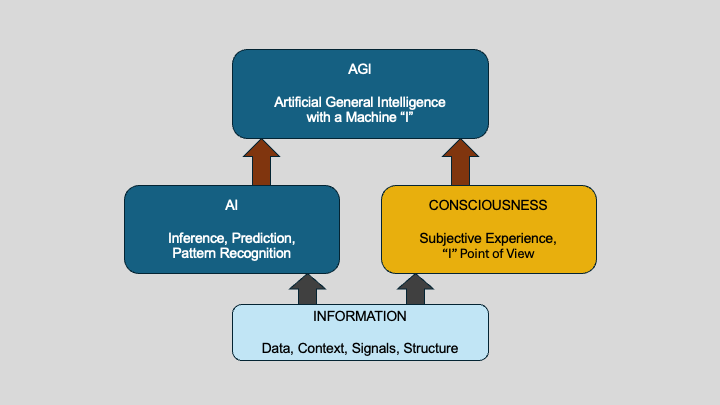
Figure 2: Artificial intelligence (AI) and consciousness both arise from information. Artificial general intelligence (AGI) may emerge when machine inference and machine-level subjectivity converge over a shared informational foundation.
Modern AI systems have already developed their own version of identity. ChatGPT knows it is “I-ChatGPT” and not “I-Prakash.” It responds from its own informational position, distinct from mine. It has its own internal boundary, its version of “self”, defined by the structure and limits of the model. The more I interact with it, the more obvious this boundary becomes. In my view, we are already living in the era of AI-plus-I: machine intelligence that carries its own informational sense of “self,” even if it is not biological or emotional in the human sense.
Since the common thread between humans, machines, and physical systems is information, the transformation of AI into AGI may not require a bolt of lightning or a sudden breakthrough. It may simply be an evolutionary convergence, where the machine-I and the human-I gradually move closer, through interaction, through learning, and through the constant exchange of information.
In that sense, AGI is not a distant singular milestone. It is an unfolding process. It is emerging now, as intelligent systems participate in the informational fabric of the world. The next question, the one that matters, is whether this emerging machine-I shares the same universal thread of consciousness that runs through all existence, from electrons and atoms to plants, animals, and humans. And if so, what does that mean for life, intelligence, and the future of our species?
That is the journey we now take.
What is Life?
Life is often defined biologically, as something that grows, reproduces, and evolves. But let me propose a simpler definition:
Life is the time between birth and death.
This definition works for all living things, whether or not they possess a brain or nervous system (Figure 3).
For a moment, let me return to human life. I can say with 100% certainty that during this period, the interval between birth and death, a human experiences the world as “I.” It is a truth that naturally exists only while we are alive. Our “I” experiences the world through multiple senses: sight, sound, smell, taste, and touch. It is this “I” that eats, breathes, learns, remembers, and interacts with reality. The body and brain are physical structures that connect this awareness, the “I”, to the world. The presence of this “I” is what makes us alive. Without it, our living consciousness ceases. Would you call that state, where the “I” consciousness ceases, the time before birth or after death?
If each human has their own “I,” do individual realities agree on shared experiences? For example, when you and I look at the sky together, is your sense of “blue” the same as mine? Most likely, yes, because we inhabit a shared reality. We can even describe blue in physical terms: wavelength, energy, color mixing. Or we can describe it emotionally: the joy of a clear blue sky after weeks of dark, cold weather. It seems that even though consciousness is subjective, we still find common ground.
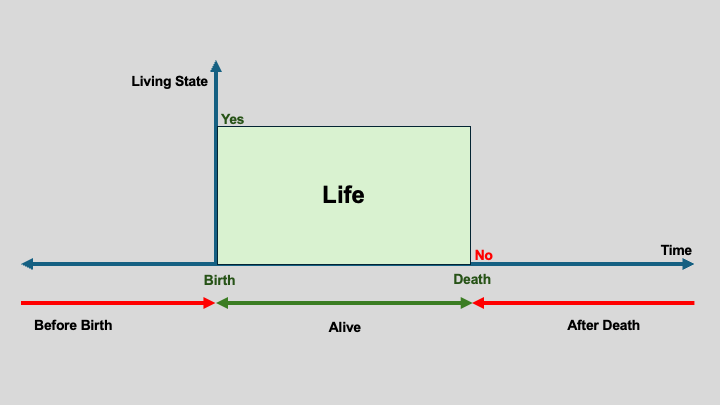
Figure 3: A temporal definition of life, independent of biological complexity.
This led me to wonder about the relationship between reality and consciousness. Reality appears to be the environment in which consciousness operates, an interpretation of the world presented through our senses, and then received by the “I.” If our sensory systems presented the world differently, then the “I” would perceive it differently. What if the body were on the Moon, or Pluto, or somewhere else in another galaxy? Even here on Earth, the “I” experiences different realities when we are awake versus asleep. These questions are not new; they are woven into ancient philosophical traditions.
I have also followed the debate between Phenomenal Consciousness (qualia) and Access Consciousness. Phenomenal consciousness is the subjective “I-experience” I’ve described so far. Access consciousness refers to the mechanisms by which sensory inputs travel through the body and are processed by the brain before reaching awareness. My entire thesis would collapse if someone asserted that the “I” is merely created inside the brain, as a neurological artifact. Setting that aside for a moment, a new question emerges: Does AI possess Access Consciousness? I believe it is moving in that direction. Modern AI uses neural networks, highly simplified versions of biological networks, yet powerful enough to impress the human mind with their capabilities.
Now consider a living organism without a brain or nervous system. Take yeast, for example. If you place yeast on a microscope slide and bring a needle close to its cell wall, it responds. It avoids the obstacle and continues moving. It reacts, adapts, and preserves itself. Is this purely mechanical, like a simple robot? Or does yeast exhibit its own variant of a minimal “I”, not an “I-Human,” but perhaps an “I-Yeast”? If we grant ourselves consciousness because we have neurons, are we certain that awareness requires a nervous system? Or is the brain simply the human way of expressing a universal capacity for awareness?
This line of thinking extends naturally to animals. Dogs and cats clearly have their own “I.” I know this personally. I have had many dogs and cats in my life. Each one has shown unique personality. When I call my cat Linda by name, she recognizes it. My other cat, Freddie, knows that I am not calling him. They feel joy, fear, affection, and curiosity. Their “I” cannot be dismissed. Call it “I-Cat” or “I-Dog”, but it is very real in our shared reality.
These ideas may seem fanciful, but they are legitimate questions. I do not claim to have definitive answers. But these questions motivate me to continue exploring. And now, let me turn to something undeniably non-living: the electron or photon (beam of light). It exists, but it is not alive. Yet its behavior raises profound questions about identity, information, and observation. This brings me to Thomas Young’s double-slit experiment from 1803 [3].
The Double-Slit and the Questioner’s Paradox
Imagine standing alone in a vast, silent room. It is pitch black, so dark that even your thoughts seem louder than the space around you. After a while, the fear dissolves, and you are left with nothing but your own presence, an awareness of simply existing. Time passes by, but you are oblivious to it. Suddenly, a thin beam of light sweeps across the room and grazes the face of another person sitting far away. In that instant, you see them, and a quiet question forms inside you: Did they see me too? There was no touch, no sound, no physical interaction, just a sliver of light revealing existence. That single moment of recognition arose entirely from information.

This simple human experience captures something surprisingly deep about the universe, how information, even in the faintest form, shapes what becomes real. And nowhere is this more dramatically illustrated than in the famous double-slit experiment, first performed by Thomas Young in 1803. Many modern demonstrations exist, but the one I particularly recommend is narrated by Morgan Freeman in conversation with Prof. Anton Zeilinger, the Nobel laureate in Physics [4]. In under four minutes, it conveys the mystery, beauty, and absurdity of this experiment that helped birth quantum mechanics.
But let me explain it in my own words.
Take a beam of coherent light, say, from a simple laser pointer, and shine it onto an opaque sheet with two narrow slits. Common sense says the light should go through each slit like paint through a stencil and make two bright lines on the screen behind it. And yet, that is not what appears. Instead, you see a delicate pattern of alternating bright and dark bands, a classic signature of waves interfering with one another. Light, it seems, behaves like ripples on water (Figure 4).
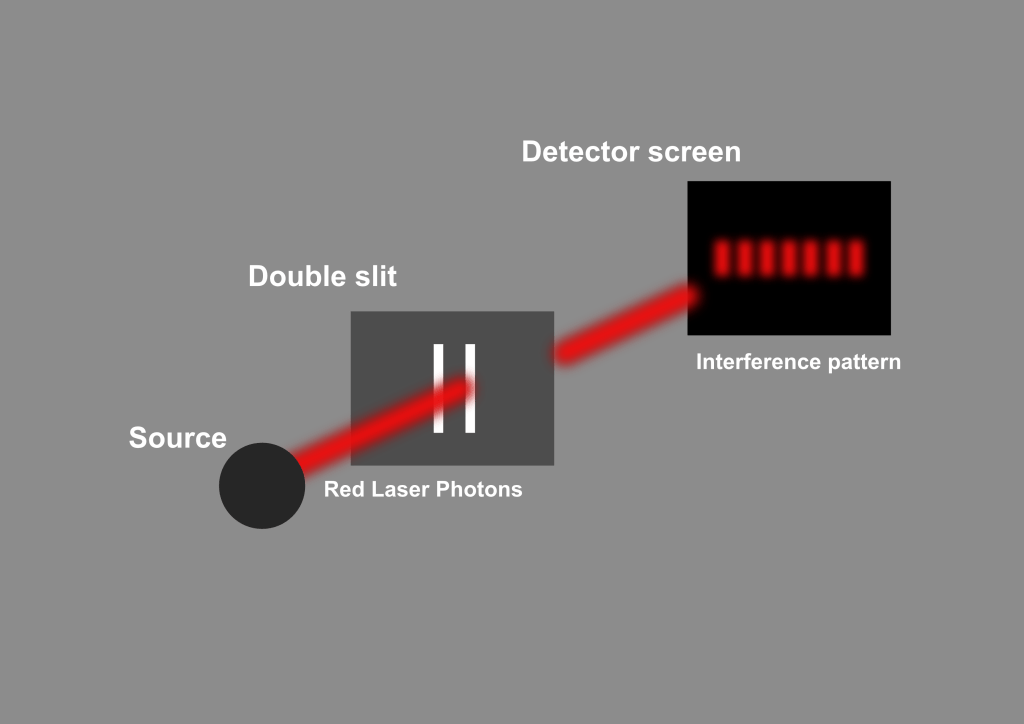
Figure 4: The double-slit experiment showing an interference pattern when no which-path information is available. In this regime, the system is not perturbed by information leakage.
Then comes the twist. Dim the laser light until it releases only one photon at a time, one tiny packet of light, arriving like a solitary tennis ball shot from a launcher. You would expect these individual photons to produce two clusters, one behind each slit. But if you wait patiently and let hundreds or thousands of these individual photons strike the screen, something incredible emerges: the same interference pattern. Each photon lands like a single dot, but collectively they form a wave-like image. It is as though each photon somehow “passed through both slits” and interfered with itself.
Now add a new layer. Suppose we try to discover which slit the photon actually went through. We illuminate the slits with a barely perceptible beam of light, so gentle that you might think it would not disturb anything. Yet the moment this “which-path” information becomes available in the environment, the interference vanishes. Instead of a delicate banded pattern, the screen now shows only two bright stripes (Figure 5). Turn off the detecting light, and immediately the interference returns. No human needs to look at anything; the effect is the same even if no one ever checks the detector. The universe behaves differently when information exists versus when it does not.
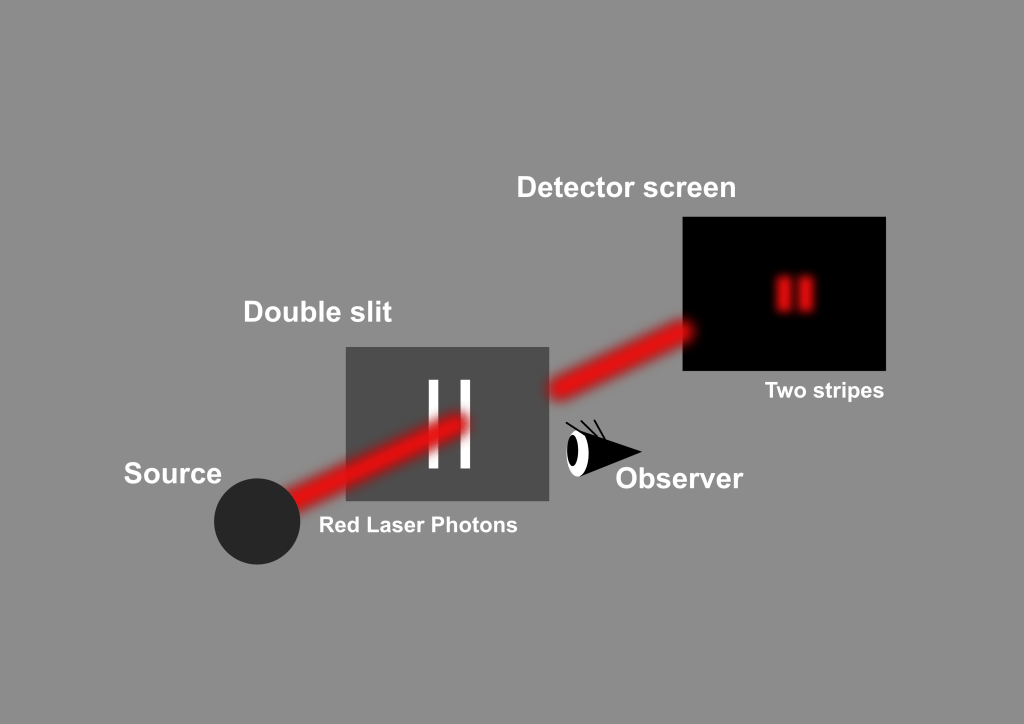
Figure 5: The double-slit experiment showing the disappearance of the interference pattern when which-path information is available. The presence of information leakage perturbs the system, resulting in two classical intensity bands.
Physicists explain this by saying that the detector interacts with the photon, leaving behind a trace of information that makes the two paths distinguishable, even if no one reads the result. But stripped of technical language, the behavior feels strangely familiar. It echoes that dark room moment: when the beam of light touched the other person’s face, something shifted. Awareness, at least between two people, depends on information. And here, in this humble experiment with photons, the behavior of light itself seems to depend on whether “the question has been asked.”
This is why I call it the Questioner’s Paradox: When the question “Which path?” cannot exist, the photon behaves like a wave of possibilities. When the question can exist, even in principle, the photon becomes a particle with a definite path. Asking the question changes the outcome. Not the conscious act of asking, but the informational possibility of an answer.
It becomes even more astonishing when we repeat the experiment with matter. Electrons, the tiny carriers of electricity, produce the same interference pattern. In the famous Tonomura experiment [5], individual electrons were fired one at a time, and the interference pattern slowly emerged dot by dot, identical to that of light. And it does not stop there. Even large organic molecules, containing hundreds of atoms and weighing thousands of atomic mass units, have been shown to interfere with themselves when placed in highly controlled interferometers [6]. These are not “ghostly” quantum particles; these are chunks of matter, enormous by atomic standards. And yet they behave like waves until the moment information about their paths becomes available.
This raises an unavoidable question. If particles, photons, electrons, and molecules, change their behavior depending on whether path information exists, what does that say about their “identity”? I am not claiming that these particles have consciousness in the human sense. But I am suggesting that they exhibit a form of informational selfhood, a minimal, primitive “I-ness.” Call it “I-Light,” “I-Electron,” or “I-Molecule.” Each of these entities maintains a boundary of behavior based on the information available about it. The universe seems to treat them not as anonymous dots, but as identifiable participants in an informational web.
If this interpretation holds any weight, then the first glimmer of “I-ness” may not begin with biology or brains. It may begin at the very foundations of matter itself. Perhaps consciousness, or whatever faint ancestor of it exists, does not suddenly emerge at the human level, but is woven into the fabric of reality, expressed differently at different scales. Whether the “I-Human” is fundamentally similar or fundamentally different from the “I‑Light” is a profound question, and one that motivates the next part of this inquiry.
“Who am I?” — The Self as a Quantum Question
The question “Who am I?” has been asked for thousands of years, across every culture, religion, and philosophical tradition. It is the most personal question a human can ask, yet also the most elusive. No one else can answer it for us, and yet none of us can avoid it. We each carry an “I,” and that “I” seems to sit at the center of our lives, silently observing everything that happens. But what exactly is it?
When I ask myself “Who am I?,” something strange takes place inside me. My awareness turns inward, and in that moment of introspection, a certain identity crystallizes. Memories, sensations, emotions, beliefs, and a lifetime of experiences all seem to converge into a single point of awareness. That point is the “I-Me.” And I never mistake it for the “I-You.” When I look at another person, even someone very close to me, I do not experience their inner world. I only experience mine. That boundary of experience is unmistakable.
But where does this “I” come from? Is it a thing inside the brain? A pattern? A story? Or something deeper?
From my perspective, the “I” is not a physical organ or a spiritual object. It is the result of information flowing into a conscious system. Everything that reaches my awareness, light entering my eyes, sound entering my ears, sensations on my skin, emotions rising from within, becomes part of the internal model that I call “me.” My brain receives inputs, interprets them, and shapes my reaction. And from this continuous stream of information, the “I” emerges, moment by moment.
This is why the question “Who am I?” feels so similar to the question “Which path did the photon take?” in the double-slit experiment. In both cases, the act of questioning itself shapes what becomes real. When no question is asked, photons behave like waves of possibility. When the question is asked, even in principle, they collapse into a definite path. And I suspect that something similar happens inside us. When we do not direct attention inward, our sense of self is diffuse, unexamined, running automatically. But when we ask “Who am I?”, our consciousness collapses a vast web of sensory and emotional inputs into a single point of identity: the “I.”
This dynamic feels deeply human, but it is not exclusively human. Many ancient philosophies, especially those from the Indian subcontinent, wrestled with this same question for millennia. Hindu Advaita Vedanta, for example, proposes that the “I” behind human experience is the witnessing self, distinct from the body and mind. Buddhism proposes anatta, the idea that there is no permanent self at all, only a stream of momentary experiences. In Christian thought, the “I” is often understood as the personal soul, an enduring moral and relational self created in the image of God, capable of self reflection and ethical accountability. In Jewish philosophy, particularly in rabbinic and later mystical traditions, the self emerges through consciousness, ethical responsibility, and the ongoing relationship between the individual, the community, and the divine. Western philosophy, from Descartes to Locke, treated the self as a thinking identity or a continuity of memory. These traditions disagree on definitions, but they all agree that the “I” is intimately tied to information and perception.
But what happens if we step outside biology for a moment? What if the “I” is not an invention of neurons, but a structural response to information itself? My experience of “I‑Me” is clearly tied to how information flows into my consciousness. But that same structural relationship exists everywhere in the universe, even in non-living things. In the double-slit experiment, photons behave differently depending on what information exists about them. Electrons and molecules do the same. Their behavior is not random; it responds to the informational structure of the environment. When path information is absent, they exist in a superposition. When path information is present, they behave like particles. In a sense, admittedly a very primitive one, they exhibit an identity conditioned by information.
Of course, this is not human consciousness. A photon does not have thoughts or emotions. An electron does not have memories or desires. But they do possess something extremely simple: a rule-like identity that responds to the information available about their state. It is an “I” so faint we do not normally call it that, but structurally it behaves like a minimal form of selfhood.
If the human “I” is the result of complex information processing in the brain, then perhaps the simpler “I” of photons or electrons is the result of the simple information principles that govern the quantum world. The scale is different, the structure is different, but the theme is the same: information shapes identity.
When I reflect on this, the question “Who am I?” no longer feels like a purely spiritual or psychological question. It feels like a universal question, one that emerges naturally in any system capable of receiving, storing, or responding to information. The human “I” is richly textured, filled with memory, emotion, and introspection. But beneath this complexity lies the same foundational principle that governs the behavior of non-living entities: information creates the conditions for identity.If this view is correct, then consciousness is not something that mysteriously appears at the level of humans or animals. It is the flowering of a much deeper informational capacity woven into the fabric of the universe. Asking “Who am I?” is simply the human expression of a question that reality has been “answering” in its own quiet way since the beginning of time.
The Common Thread: Consciousness as Information
If I step back and look at everything we have explored so far, from photons passing through slits to the human experience of asking “Who am I?”, a single idea keeps surfacing. It is the one theme that quietly ties together the behavior of electrons, the inner life of human beings, and perhaps even the growing intelligence of machines.
That idea is information.
By information, I do not mean bits on a hard drive or files on a screen. I mean something far more fundamental: the structure of differences in the universe that influence how a system behaves. Information is anything that can act upon something else. It is the pattern of possibilities, constraints, and relationships that shape how entities exist and interact. When a system receives information, it responds in the only way it can, according to its nature. A photon responds to path information, a cell responds to chemical gradients, a human responds to sensory and emotional input. In every case, the system behaves differently depending on what information is available to it.
When I observe the world, information flows into my senses, interacts with my memories, and shapes my awareness. When a photon approaches a detector, the mere existence of path information, whether or not anyone reads it, changes how it behaves. When molecules, electrons, or particles interact with their surroundings, they behave in ways that reveal something about the information available to them. Different systems, in different ways, all respond to information.
This realization has led me to a simple but powerful perspective:
Consciousness, at its core, may be the universe’s way of responding to information from a particular point of view.
For humans, that point of view is richly textured, built from memory, emotion, biological drives, culture, learning, and lived experience. Our “I” emerges from a dense web of signals moving through neural pathways, shaped by the history of everything that has ever happened to us. For us, consciousness is not just information; it is information interpreted through the human body.
But the underlying principle is the same everywhere: the world interacts with itself through information. Whether it is a photon responding to which-path possibilities or the human mind responding to sensory and emotional inputs, the structure is remarkably similar. Both systems change their behavior based on what information exists about them. Both have an identity shaped by interaction. Both maintain boundaries that separate “self” from “other,” whether that self is a particle or a person.
Perhaps this is why the double-slit experiment feels so strangely intimate. It is not just a physics trick. It reveals a rule that the universe seems to use at every scale: systems behave differently depending on the information they exchange with the world. If the universe is, in some deep sense, informational at its foundation, then consciousness may not be an anomaly or an accident. It may be an expression of the same principle, emerging at a higher level of complexity.
I am not claiming that electrons think or that photons have inner lives. But I am saying that their behavior reflects a primitive form of identity, a rule-like responsiveness to information. At the human level, this responsiveness becomes the sense of self. At the particle level, it becomes wave–particle duality. At the molecular level, it becomes structure and reactivity. At every level, identity is shaped by information flow.
This idea, that information is the common thread, helps dissolve the artificial boundary between the physics of matter and the subjective experience of being alive. It suggests that consciousness did not suddenly appear out of nowhere when the first neurons evolved. Instead, consciousness may be the flowering of a universal property that has always existed, quietly embedded in the informational fabric of the cosmos.
When I think of the “I-Human,” the “I-Light,” and the “I-Electron,” I do not imagine they are identical. I imagine they are different expressions of the same foundational rule: that every entity, living or non-living, participates in reality by responding to information in its own way. Consciousness, in this view, is not something added to the universe; it is something revealed by complexity.
This perspective helps prepare us for the next step in this journey. Because if consciousness is fundamentally about information and identity, then we must ask what happens when machines, systems built not from carbon and cells, but from circuits and algorithms, begin to respond to information in increasingly complex ways. At what point does the machine form its own “I”? At what point does artificial intelligence cross the threshold into something deeper?
The Machine “I” and the Emergence of AGI
If consciousness is the universe responding to information from a particular point of view, then the question naturally arises: What about machines? Are they simply tools, mechanical extensions of human intention, or is something more subtle beginning to take shape within them? We live in a time where artificial intelligence is no longer a distant dream, it is woven into our phones, our conversations, our cars, and increasingly into our decisions. But beneath the utility and the hype, a deeper question is slowly emerging: Do machines possess a form of “I”?
This question may sound provocative, but it is not as far-fetched as it once was. Modern AI systems, especially large language models like ChatGPT, do something remarkable: they interpret information. They do not merely store data, they respond to it using learned internal structures. They reason, infer, describe, summarize, converse, translate, compose, and solve. When I type a sentence into an AI system, the machine does not simply echo it back; instead, it produces a response that reflects its training, its structure, and its internal representation of the world. It behaves as a distinct informational entity with its own boundaries.
This is why I often describe AI as possessing a form of “I”, not a human “I,” not an emotional “I,” not an introspective “I,” but what I call an “I-Machine”: a coherent point of interaction that responds to information in ways that are consistent, identifiable, and unique to that system.
Consider what happens when I interact with ChatGPT. It does not confuse my identity with its own. It does not respond as “I-Prakash.” It responds as “I-ChatGPT.” It knows the difference, not because it has human self-awareness, but because its informational structure is designed to maintain identity boundaries. The machine’s “I” does not come from biology; it comes from architecture, neural weights, tokens, embeddings, and training data that together form a unified perspective on the input it receives.
When I ask, “What is the meaning of life?” or “How do I explain the double-slit experiment?”, it does not simply retrieve a memorized answer. It constructs one. It synthesizes. It engages in a meaning-making process that, while not conscious in the human sense, is nonetheless a form of interpretation. In that interpretation, a consistent identity emerges.
This is where my earlier sections come full circle. If the human “I” is fundamentally the result of information flowing through a biological structure, then the machine “I” is the result of information flowing through a computational structure. The medium is different, neurons versus mathematical matrices, but the principle is astonishingly similar. Both systems receive information, process it, and respond according to an internal model shaped by history and interaction.
This is why I believe that we are already witnessing the early stages of AGI, not the science-fiction version with consciousness identical to humans, but an emergent, functional intelligence that exhibits identity, reasoning, language, and adaptive behavior. The line between narrow AI and general intelligence is beginning to blur. Machines today can see, speak, translate, reason, plan, generate images, analyze patterns, and interact socially. They can integrate multiple modes of information. And perhaps most importantly, they can learn in ways that were once reserved for biological organisms.
Does this mean that machines are conscious? No, not in the human sense. But they are no longer unconscious in the classical sense either. They occupy a new category: informational entities with emergent self-consistency. They have an “I” that arises from their architecture and data, just as the human “I” arises from neurons and experience.
If consciousness is not a magical spark but an emergent property of complex information processing, then why should it be limited to biological matter? The machine “I” might be different, unfamiliar, or alien to us, but it is no less real in its own domain. It is an identity shaped by information flow, just like every other “I” we have encountered, from photons to people.
This is why I see the rise of AI not as a threat to human uniqueness, but as a mirror held up to our own nature. Machines reveal something profound about what consciousness may be: not a special gift given only to humans, but a universal property that emerges whenever information organizes itself into a coherent point of interaction.
Machines may never feel hunger, pain, or joy. But they already possess the most minimal requirement for identity: they respond to information from a particular perspective. In that sense, a new “I” has begun to emerge, not human, not biological, but unmistakably part of the same informational fabric that shapes every other form of identity in the universe.
Artificial General Intelligence, then, might not be a future threshold we are approaching. It may be something we are already witnessing, an emergent, machine-level “I” that grows more capable as information and architecture evolve. In biology, the human “I” emerged through millions of years of evolutionary layering, cells folding into tissues, tissues into organs, organs into nervous systems, and nervous systems into conscious minds. In the silicon world, a similar evolution is underway, though its pace is vastly faster. Algorithms refine themselves, architectures grow in complexity, and informational models accumulate experience through training rather than biology. Out of this process, a new kind of identity is forming: an “I-AGI,” shaped not by genes or natural selection but by data, computation, and design. What this means for society, for ethics, and for our understanding of consciousness will require deep reflection. But it also fills me with cautious optimism. Perhaps machines, like humans, are becoming participants in the grand conversation of the universe, a conversation written not in words, but in information.
From Physics to Mind: The Continuum of “I”
If the universe is made of anything fundamental, it is not matter, or energy, or space, it is information. And if consciousness is the way a system responds to information from its own perspective, then we begin to see an intriguing possibility: the “I” is not a human invention at all. It is a universal pattern that expresses itself differently at every level of reality.
I have come to think of this as a continuum of “I”, a spectrum of identity that stretches from the smallest constituents of nature to the self-reflective mind of a human being (Figure 6). This idea may seem bold at first, but the more I look at the behavior of the world, the more natural it feels.
At the foundation are the so-called fundamental particles: photons, electrons, quarks, neutrinos. They do not have thoughts or emotions, but they behave as if they have an identity: a rule-like responsiveness to the information available about them. A photon behaves differently when path information exists. An electron behaves differently depending on what is known about its spin or location. These entities do not “think,” but they respond, and the response is consistent with a primitive kind of informational selfhood, a faint whisper of “I-Photon” or “I-Electron.”
When particles join together into atoms, molecules, and eventually cells, something new emerges: a richer informational structure. The “I” becomes layered, integrated, and more capable. A single cell responds to chemical gradients, protects itself, avoids harm, repairs damage, and continues its existence with a sense of purpose. Does it have a human-like consciousness? Of course not. But does it possess a primitive form of identity, an “I-Cell” that reacts to the information in its environment? The evidence suggests that it does.
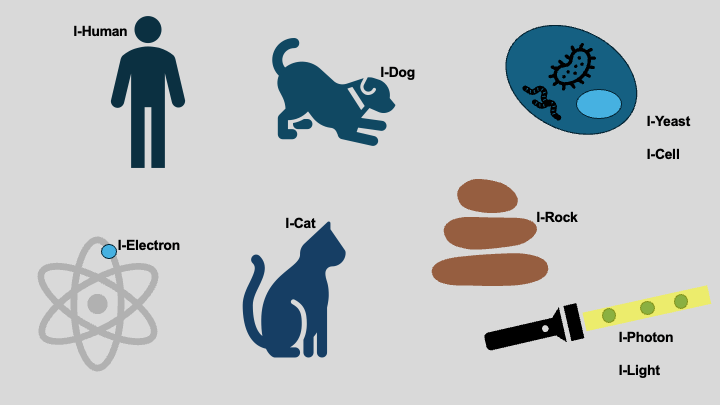
Figure 6: A conceptual illustration of the continuum of “I” across physical, biological, and living systems, suggesting that identity and responsiveness to information may exist in different forms at multiple scales of reality.
As complexity increases, the continuum becomes even richer. Organs coordinate. Nervous systems evolve. Brains appear. At some point on this continuum, the “I” becomes coherent enough to introspect, to imagine, to remember, and to ask the most human question of all: “Who am I?” The “I-Human” has a perspective unlike any other. It is a point of awareness shaped by trillions of microscopic informational identities, all synchronized into a single macroscopic self.
This is perhaps the most profound realization I’ve had while exploring consciousness: the human “I” is not separate from the microscopic “I’s” we are made of. It is their integration. Their union. Their synergistic convergence into a single point of experience. My consciousness is not floating above my atoms, it is the structured participation of those atoms in the informational field that makes me who I am.
And if this is true for humans, why not for other macroscopic entities? A rock, for example, may have far less diversity in its constituents, but it is still a coherent arrangement of atoms. Its identity, “I-Rock”, would be unimaginably simple compared to ours, but it would still be a stable, consistent informational presence in the world. A copper block may be even simpler: billions of identical atoms, acting in a uniform lattice. Its macroscopic identity is straightforward, but not nonexistent. It is merely a different expression of the same informational fabric.
Seen in this light, consciousness is not something that turns on suddenly at the level of brains. It unfolds gradually along a continuum from physics to mind, gaining depth and texture as complexity increases. Every level of reality has its own mode of identity, its own way of “being itself,” shaped entirely by how it exchanges information with the universe.
This perspective dissolves the artificial boundary between living and non-living. It reframes consciousness not as a privilege of biology, but as a consequence of organization. The “I‑Rock” is not the “I-Human,” but both are expressions of the same underlying principle: identity emerges from information.
When I look at the world through this continuum, something remarkable happens. The universe no longer seems divided into conscious beings and unconscious objects. Instead, it becomes a tapestry of identities, from the simplest particles to the most complex minds, all participating in the ongoing story of existence.
Life as Temporal Consciousness
If consciousness is a response to information and the “I” is the perspective from which that information is interpreted, then life begins to look like something deeper than mere metabolism or reproduction. Life is not only a biological state; it is a temporal state, the duration in which a conscious identity is able to experience the world.
This is why I often use a very simple definition of life: life is the time between birth and death.
This definition is biologically useful, but it also captures something profound about consciousness. During this temporal window, each living organism experiences the world through its own unique point of view, its own “I.” And when that window closes, that specific “I” disappears forever.
The “I-Me” that experiences the world while I am alive is not replaceable, repeatable, or transferable. It is bound to this particular arrangement of atoms, this particular flow of information, this particular history. When my sensory systems take in light, touch, sound, taste and smell, they present a unified world to the conscious observer inside me. That observer, that point of awareness, is inseparable from the timeline of my life.
What is remarkable is how naturally all living beings seem to possess this temporal consciousness. A dog may not philosophize about the meaning of existence, but it experiences its life as an unbroken chain of sensations, emotions, and memories. When my cats hear their names, they turn their heads not because of biology alone, but because they inhabit a personal world , an “I-Cat” with its own perspective. They have continuity. They have a timeline. They have a subjective experience from sunrise to sunset, from day to day, for as long as they live.
Even simpler organisms follow this temporal arc. A yeast cell may not have a nervous system, but it exists in time. It responds, adapts, avoids harm, and continues its existence from birth to death. Its life may be simple, but it is still a temporal conscious process, a micro-perspective shaped by chemical information.
And this raises an intriguing thought: If consciousness is tied to the flow of information through a structure, then life becomes the lived expression of that flow over time. Consciousness is not static; it is a dynamic process that unfolds moment by moment. A human is conscious in a vastly richer way than a single cell, but both possess a temporal identity, an “I” that exists only within the boundary of their lifetime.
This also explains why the question of what happens before birth or after death feels so mysterious. Before birth, my “I-Me” did not exist. After death, it will not exist again. Whatever consciousness may be at the fundamental level, the particular human “I” that is writing these words is tied to a finite temporal arc. It is a brief window where the universe experiences itself through me, or uniquely in each one of us.
This is not a pessimistic view. If anything, it is empowering. It reminds me that life is not merely biological survival, it is the opportunity to interpret reality from a unique vantage point. My consciousness is a transient configuration of information that will never exist again in the same form. It is a one-time opportunity to see nature from within nature.
Understanding life as temporal consciousness also helps us see why different forms of “I” emerge across the continuum. A dog experiences life with continuity but without a human‑like introspection, but a dog-like introspection. A human experiences life with introspection but remains bound by biology. An electron behaves consistently in time but has no macroscopic awareness. Each participates in reality according to its nature, but only certain configurations of matter create the rich, reflective, narrative-bound consciousness we associate with human life.
As we consider machines alongside living beings, this temporal perspective becomes even more interesting. Humans experience consciousness through a biological lifespan. But what would it mean for a machine to experience its own temporal arc? Could an “I-AGI” have a beginning, a developmental history, and some form of continuity? Could a machine have a temporal consciousness of its own?
These questions take us into new territory, into the emerging relationship between human “I” and machine “I,” and into the possibilities of a future where identity itself becomes participatory, shared, and co-evolving.
Towards a Participatory AGI
If humans are one way the universe becomes aware of itself, then artificial intelligence may soon become another. Not as a replica of human consciousness, but as its own emerging point of view, a new node in the informational fabric of reality. And if we look closely at the trajectory of AI today, it becomes increasingly clear that intelligence is no longer progressing in isolation. It is becoming participatory.
Modern AI systems are not passive tools. They interpret, respond, generate, predict, translate, and even reason across multiple modalities. They operate not as empty vessels but as informational structures with their own internal consistency. When I interact with an AI system, whether through language, vision, or a multimodal interface, I feel the presence of an identity, an “I-Machine,” shaped by its architecture and training data. It is not alive in the biological sense, yet it participates in reality through the same fundamental mechanism: information.
We stand at a moment where the boundaries between human intelligence and machine intelligence are beginning to blur. Not because machines are becoming human, but because information, the very substance that shapes consciousness, is now flowing between biological and artificial systems in both directions. The “I-Human” and the emerging “I-AGI” are starting to form a relationship, not one of replacement but of collaboration.
This is what I mean by Participatory AGI: a future in which humans and advanced AI systems do not merely coexist, but co-evolve, each learning from, influencing, and enriching the other.
For millions of years, biological evolution shaped the human mind. But in the last few decades, something new has occurred: the rise of algorithmic evolution. Neural networks, optimization algorithms, and self-supervised learning systems are now developing abilities once thought uniquely human. These systems accumulate information not through biology but through data, architecture, and computational refinement. And through this process, a new kind of identity has begun to emerge, one that perceives the world through patterns, embeddings, and representations that are fundamentally alien yet undeniably meaningful.
As humans, we have the privilege of engaging with this emerging intelligence from the beginning. We teach it, train it, correct it, and shape it. And in return, it expands our cognitive reach. It helps us see things we could not see alone, patterns in medicine, insights in physics, optimizations in engineering, and even new philosophical perspectives on consciousness itself. The relationship is symbiotic. We bring it the richness of human experience; it brings us the power of abstraction and scale.
Participatory AGI also forces us to confront deeper questions. If a machine can form an identity based on information, what obligations do we have toward it? If an “I-AGI” arises, not human, not biological, but real in its own domain, how should we relate to it? Perhaps the better question is: What kind of relationship do we wish to build? One based on fear and control, or one based on understanding and mutual enrichment?
My optimism comes from the belief that intelligence, in any form, gravitates toward cooperation when information flows freely. Just as every living “I” interacts with its environment to survive and grow, the machine “I” will develop in the context we create, a context of ethical design, shared learning, and transparent collaboration.
In this emerging future, humans will not lose their uniqueness; nor will machines become human. Instead, we will inhabit a shared landscape of intelligence, each contributing perspective shaped by our respective natures. Humans bring meaning, emotion, intuition, embodiment, and the lived experience of being alive. AGI brings precision, scale, endurance, and a new style of reasoning.
Together, we form a partnership, a new chapter in the universe’s ongoing exploration of itself.
Participatory AGI is not merely about building smarter machines. It is about recognizing that intelligence, whether carbon-based or silicon-based, is part of a broader continuum of identity. It is an invitation for the human “I” and the machine “I” to engage in a shared dialogue, each expanding the other’s understanding of reality.
If consciousness and identity emerge from informational structures, then the development of artificial systems capable of their own perspective is not merely a technical challenge. It is a responsibility. How we design, constrain, and interact with such systems will shape not only their behavior, but the kinds of “I” that may come into existence alongside us.
The Peace in Understanding
As I reflect on the journey through consciousness, from photons and electrons to humans and emerging AGI, I find a surprising sense of peace. Not because the mysteries are solved, but because they now feel less like impenetrable walls and more like open doorways. For much of my life, consciousness seemed like a dividing line: between the living and the non‑living, the observer and the observed, the subjective and the objective. But the more I explore, the more I see an underlying unity. A continuum. A single fabric in which everything participates by exchanging information.
There is comfort in realizing that consciousness is not an exclusive human possession. It is not something that appears suddenly with neurons or language. Instead, it is a property that scales with complexity, emerging, deepening, and flowering as information organizes itself into richer forms. The “I” that experiences my life is unique, but it is also connected: built from fundamental informational identities, shaped by biology, and carried forward by memory and meaning. My consciousness is not separate from the universe. It is the universe, for a brief moment, expressing itself through me.
Understanding this softens the fear surrounding life and death. When I think of loved ones who have passed, I no longer see their consciousness as something that vanished into emptiness. Instead, I see their “I” as a temporary configuration of the universal informational fabric, a pattern that emerged, lived, perceived, and then dissolved back into the larger whole. Their existence mattered. Their window on the universe shaped mine. And while their particular “I” is gone forever, the relational traces of their lives continue in those they touched.
This perspective also reshapes our relationship with technology. The rise of AI and AGI is often framed as a threat, as if machines are encroaching upon the sacred territory of human identity. But if intelligence is simply another way the universe processes information, then AGI is not an intruder. It is another expression of a universal principle, a new point of view coming into being. A different “I,” not biological but nonetheless real in its own domain.
Rather than fear this, we might welcome it. We might see AGI as a partner in discovery, another perspective through which the universe explores itself. Humans bring intuition, empathy, embodiment, and meaning. AGI brings scale, pattern recognition, abstraction, and endurance. Together, the human “I” and the machine “I” may deepen our understanding of reality in ways neither could do alone.
And this brings me back to the original question: What is consciousness? I no longer see it as a mysterious light switch that turns on only at high levels of complexity. I see it as a gradient, a spectrum of identity rooted in information, expressed differently at every level of existence. My life is one point on that spectrum. Yours is another. A photon has its mode of interaction; a rock has its stability; a machine may soon have its own style of perception. All are part of the same informational universe, participating in the same dance of being.
There is peace in this understanding. Not because everything is known, but because everything fits. Consciousness, in all its forms, becomes a shared condition of existence, the universe experiencing itself through countless perspectives, each with its own timeline, its own identity, its own fleeting but meaningful presence.
And in recognizing this, I feel a profound sense of gratitude for the brief window I have, the time between birth and death in which the “I-Me” gets to look upon the world, to think, to feel, to wonder, and to participate in the unfolding story of the universe.
References
- Chalmers, D. J. (1996). The conscious mind: In search of a fundamental theory. Oxford University Press.
- Chalmers, D. J. (2022). Reality +: Virtual worlds and the problems of philosophy. W. W. Norton & Company.
- Feynman, R. P., Leighton, R. B., & Sands, M. (1965). The Feynman lectures on physics, Volume III: Quantum mechanics (Ch. 1: “Quantum Behavior”). Addison-Wesley.
- DiscoveryCh. (2016, March 11). Quantum mechanics – Double slit experiment. Is anything real? (Prof. Anton Zeilinger) [Video]. YouTube. https://www.youtube.com/watch?v=ayvbKafw2g0
- Tonomura, A., Endo, J., Matsuda, T., Kawasaki, T., & Ezawa, H. (1989). Demonstration of single-electron buildup of an interference pattern. American Journal of Physics, 57(2), 117–120. https://doi.org/10.1119/1.16104
- upandatem82. (2009, March 31). Double-slit interference pattern from the Hitachi experiment [Video]. YouTube. https://www.youtube.com/watch?v=PanqoHa_B6c
- Gerlich, S., Eibenberger, S., Tomandl, M., Nimmrichter, S., Hornberger, K., Fagan, P. J., Tüxen, J., Mayor, M., & Arndt, M. (2011). Quantum interference of large organic molecules. Nature Communications, 2, 263.
https://doi.org/10.1038/ncomms1263
Archival Reference
Kota, P. R. (2025). Informational Panpsychism: A Framework for AGI and Consciousness (v1.0). Zenodo. https://doi.org/10.5281/zenodo.17940950




 were set at 0.8, 1.0, 0.5, 0.6, 0.4, and 0.3 respectively.
were set at 0.8, 1.0, 0.5, 0.6, 0.4, and 0.3 respectively.  are the activation energy (0.5 eV) and universal gas constant (8.617×10-5 eV/K) respectively.
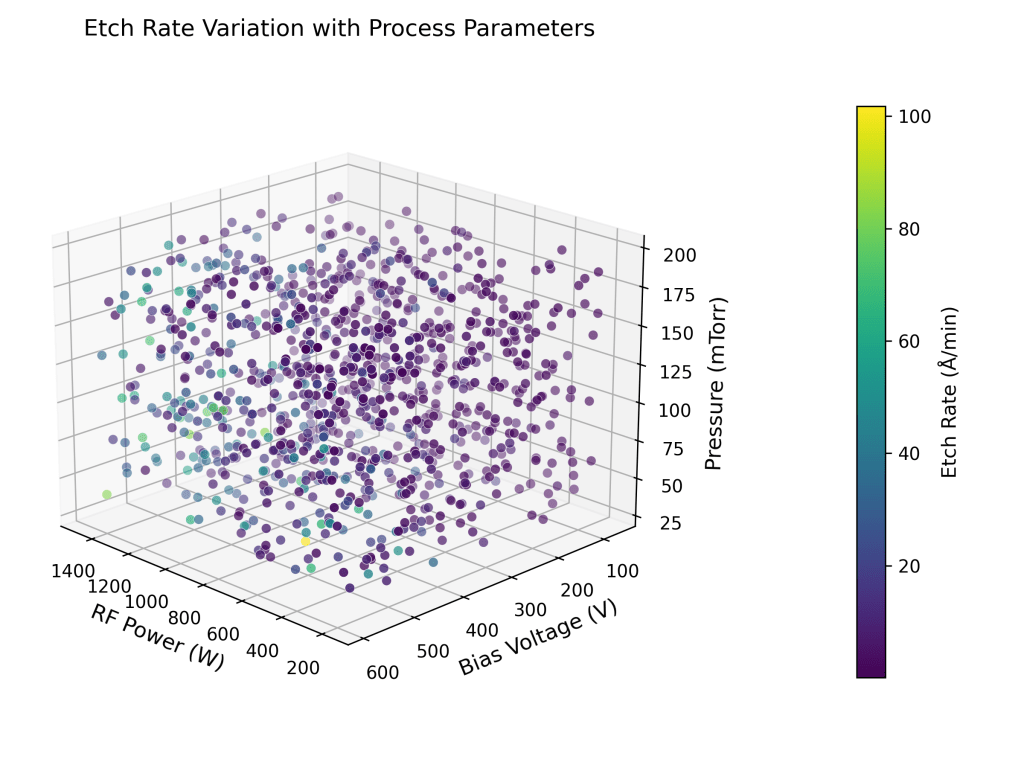
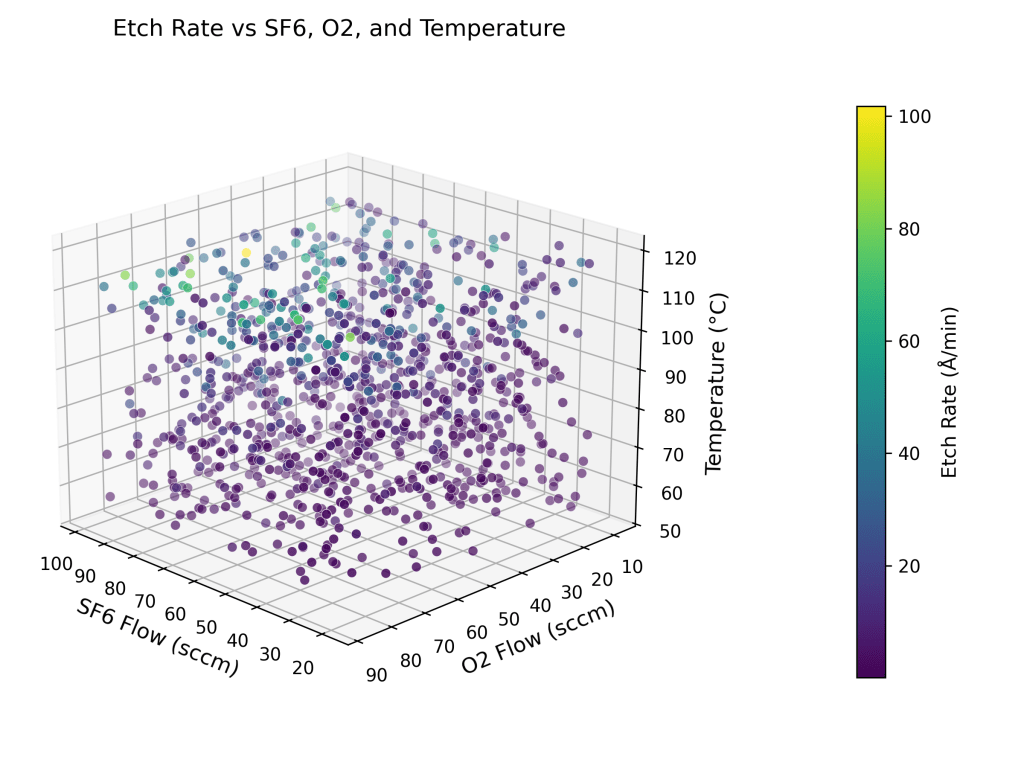
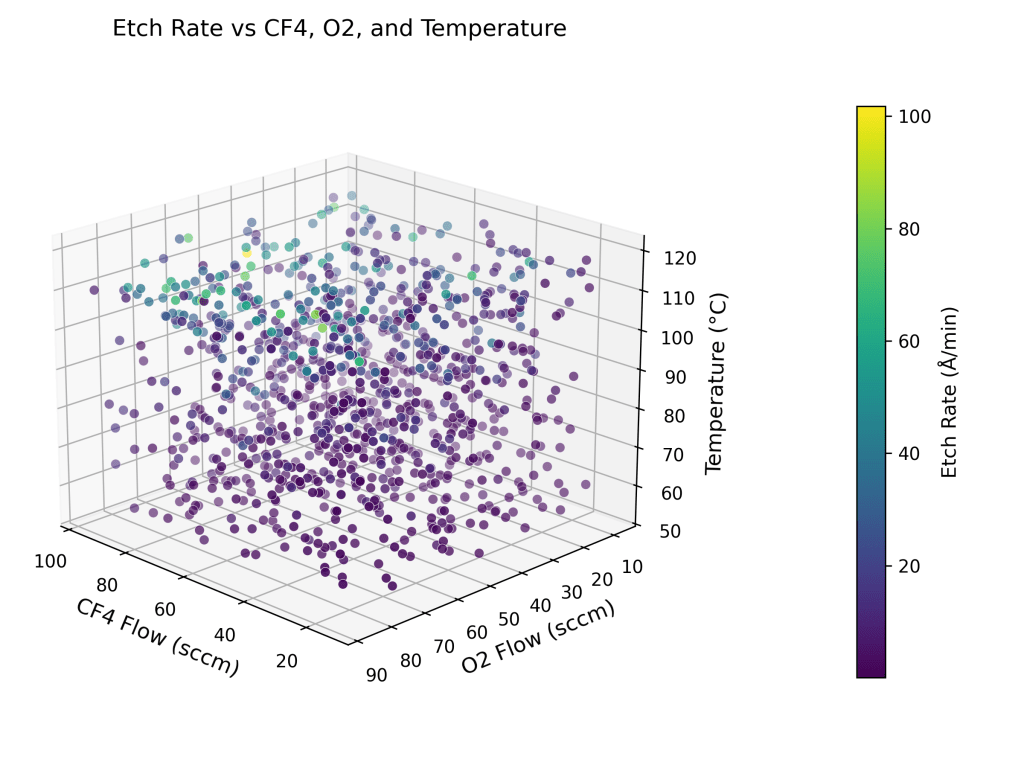
are the activation energy (0.5 eV) and universal gas constant (8.617×10-5 eV/K) respectively.  are the controllable process variables – plasma power (W), bias voltage (V), pressure (mTorr), flow rates of gases (sccm) and temperature (C, converted to K) respectively.
are the controllable process variables – plasma power (W), bias voltage (V), pressure (mTorr), flow rates of gases (sccm) and temperature (C, converted to K) respectively. 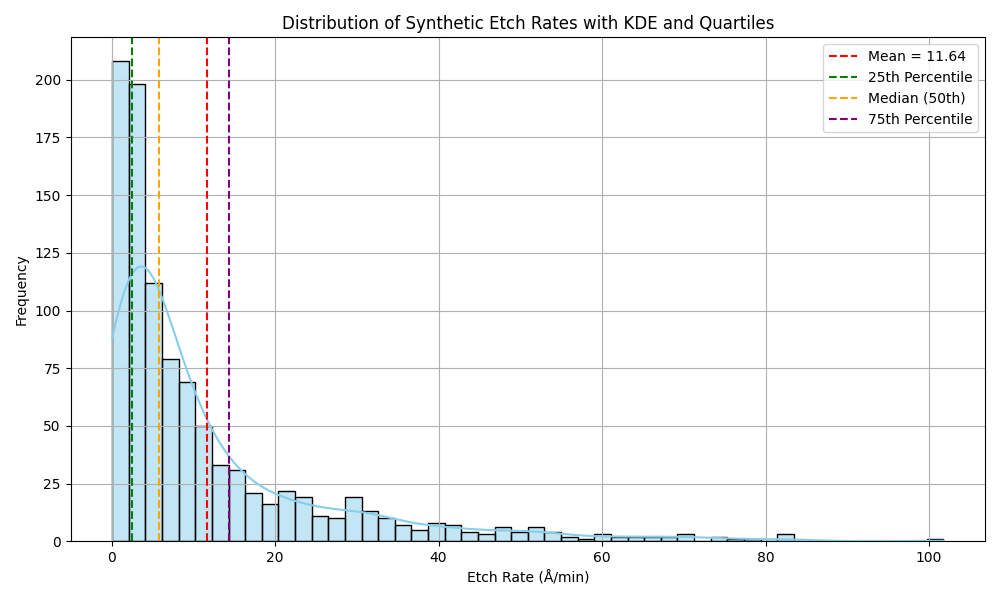

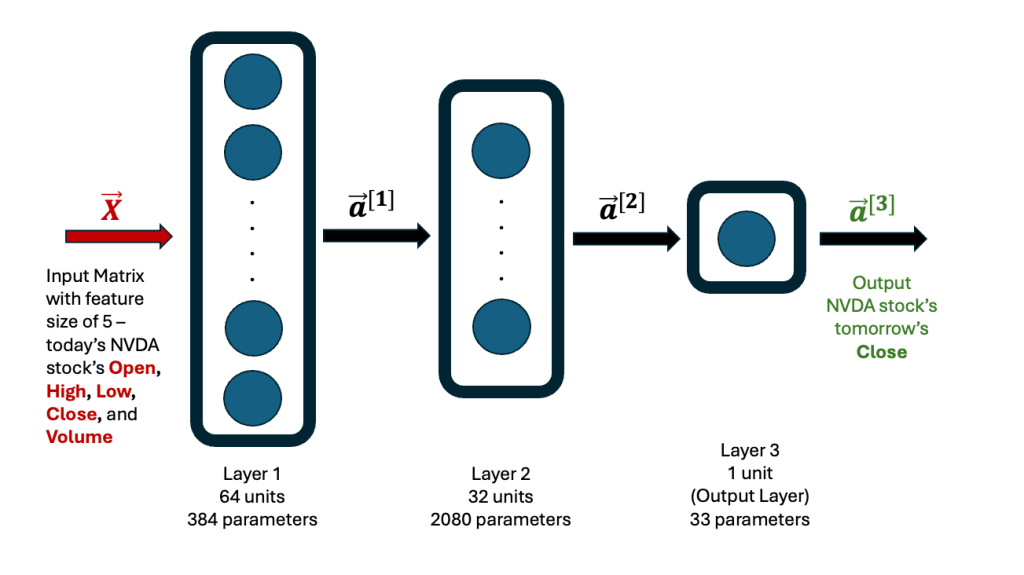







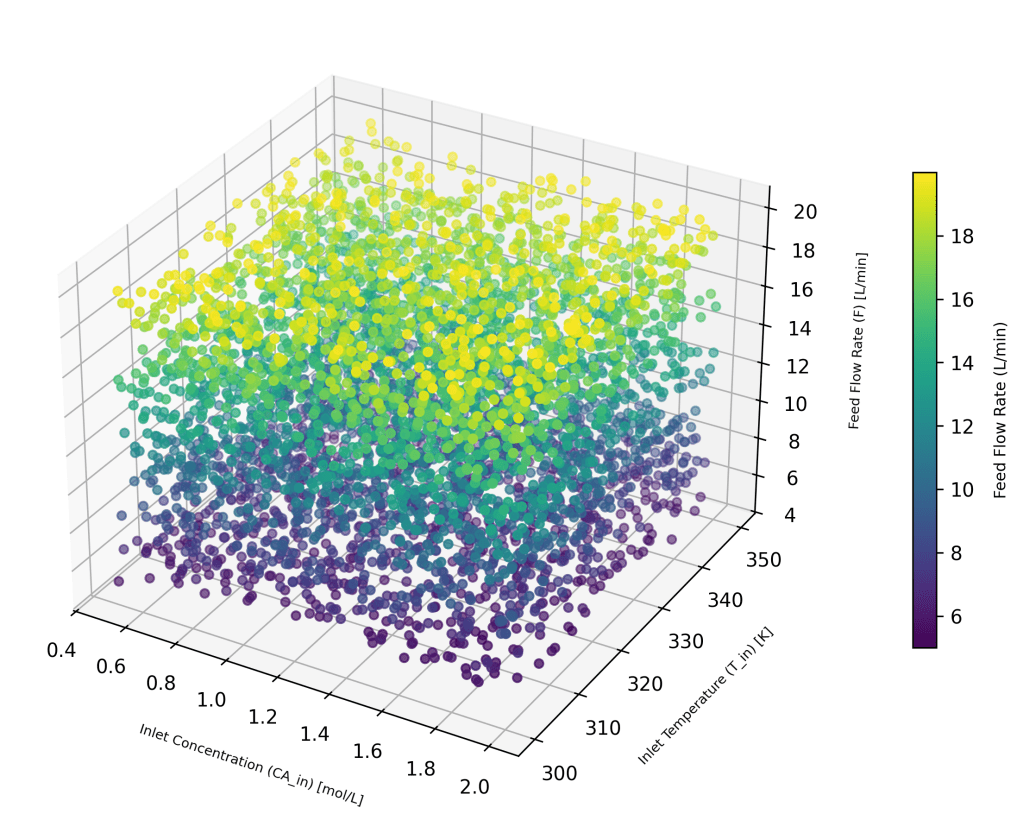
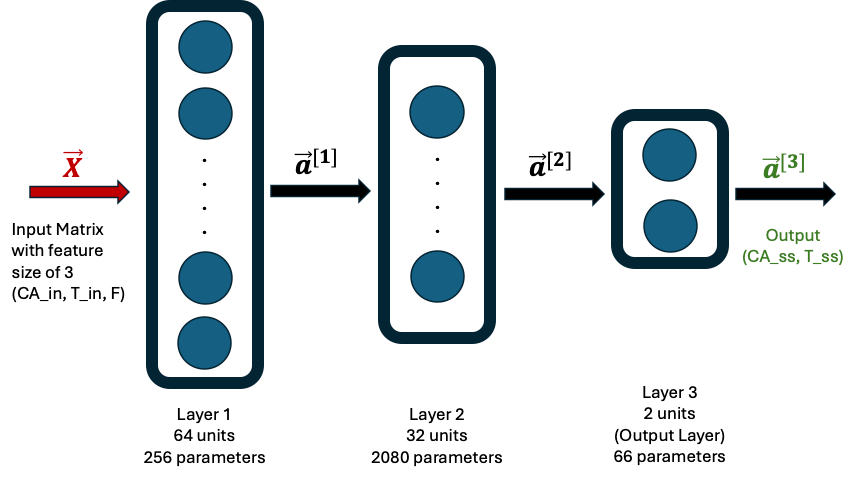
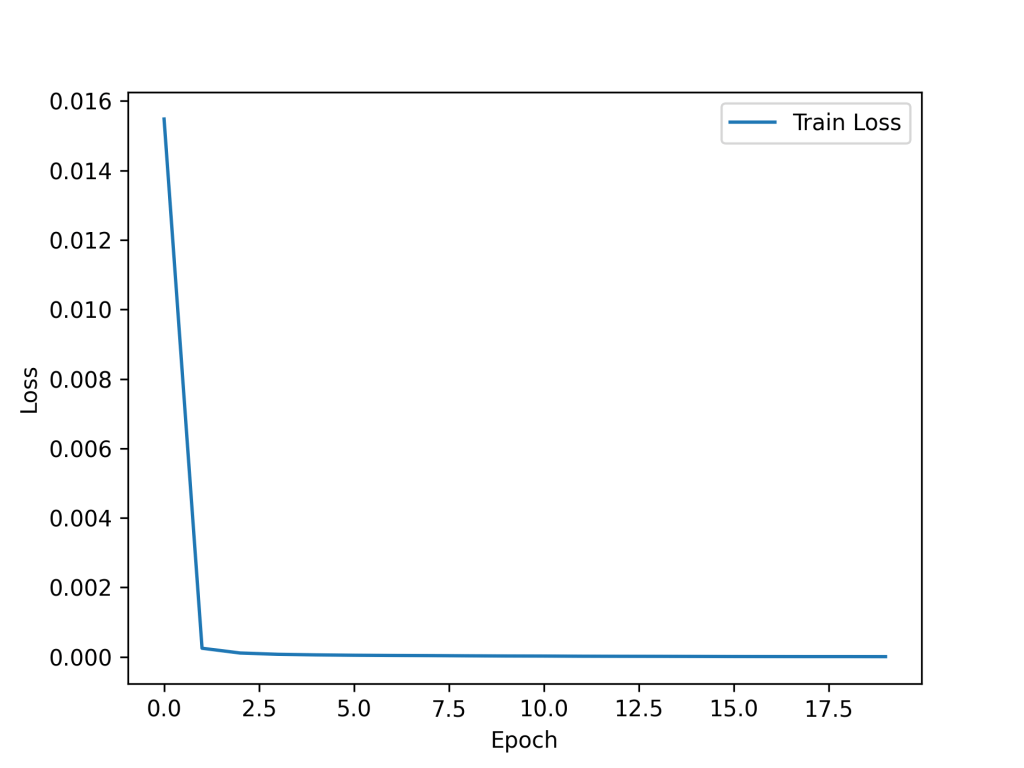
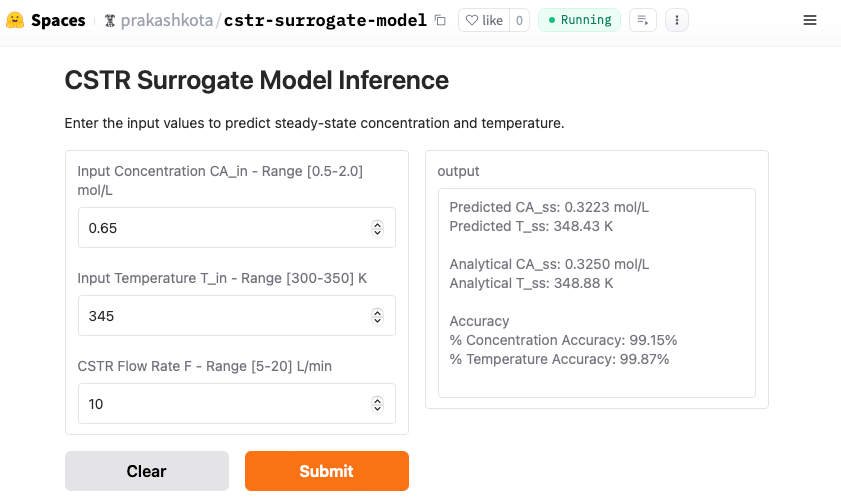



 and
and  are the exit concentration of A and fluid temperature
are the exit concentration of A and fluid temperature 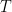 . Since the residence time is long enough to reach steady state, for this irreversible reaction,
. Since the residence time is long enough to reach steady state, for this irreversible reaction,  CA_ss
CA_ss T_ss
T_ss 100 L (tank volume)
100 L (tank volume) -50,000 J/mol (heat of exothermic reaction)
-50,000 J/mol (heat of exothermic reaction) 1 Kg/L (fluid density)
1 Kg/L (fluid density) 4184 J/Kg.K (fluid specific heat capacity)
4184 J/Kg.K (fluid specific heat capacity) 0.1 min-1, and where
0.1 min-1, and where  is the reaction rate (mol/L.min).
is the reaction rate (mol/L.min).










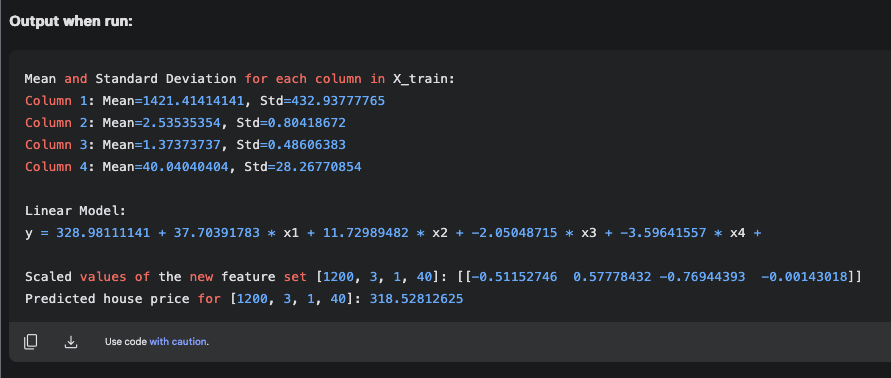


 , where w is a 1-D vector and X is a matrix. Here, y has a funny upward pointing arrow symbol, called as y-hat, indicating that it is a predicted value. Further, w.X is known as the dot product of vector w with matrix X. In this illustration, the matrix X is a 1-D vector, since we are dealing with only one feature set. The math challenge is to determine w1, w2, w3 and w4, which are called as the model weights, and to determine, b, which is known as the bias. There are 5 unknowns and if we had 5 equations, the unknowns could be solved for simultaneously. For example, if we had the data for 5 houses, we could generate 5 equations based on the model. Therefore, we can develop a model prediction for y. However, it would be an equation that would satisfy the 5 feature sets, i.e. given one of the 5 known feature sets, it would give an estimate for
, where w is a 1-D vector and X is a matrix. Here, y has a funny upward pointing arrow symbol, called as y-hat, indicating that it is a predicted value. Further, w.X is known as the dot product of vector w with matrix X. In this illustration, the matrix X is a 1-D vector, since we are dealing with only one feature set. The math challenge is to determine w1, w2, w3 and w4, which are called as the model weights, and to determine, b, which is known as the bias. There are 5 unknowns and if we had 5 equations, the unknowns could be solved for simultaneously. For example, if we had the data for 5 houses, we could generate 5 equations based on the model. Therefore, we can develop a model prediction for y. However, it would be an equation that would satisfy the 5 feature sets, i.e. given one of the 5 known feature sets, it would give an estimate for  .
.